UnifiedRegression
- class hana_ml.algorithms.pal.unified_regression.UnifiedRegression(func, massive=False, group_params=None, pivoted=False, **kwargs)
The Python wrapper for SAP HANA PAL unified-regression function.
Compared with the original regression interfaces, new features supported are listed below:
Regression algorithms easily switch
Dataset automatic partition
Model evaluation procedure provided
More metrics supported
- Parameters:
- funcstr
The name of a specified regression algorithm.
The following algorithms(case-insensitive) are supported:
'DecisionTree'
'HybridGradientBoostingTree'
'LinearRegression'
'RandomDecisionTree'
'MLP'
'SVM'
'GLM'
'GeometricRegression'
'PolynomialRegression'
'ExponentialRegression'
'LogarithmicRegression'
- massivebool, optional
In this example, as 'percentage' is set in group_params for Group_1, parameter setting of 'thread_ratio' is not applicable to Group_1. Defaults to False.Specifies whether or not to use massive mode of unified regression.
True : massive mode.
False : single mode.
For parameter setting in massive mode, you could use both group_params (please see the example below) or the original parameters. Using original parameters will apply for all groups. However, if you define some parameters of a group, the value of all original parameter setting will be not applicable to such group.
An example is as follows:
- group_paramsdict, optional
If massive mode is activated (
massiveis True), input data for regression shall be divided into different groups with different regression parameters applied. This parameter specifies the parameter values of the chosen regression algorithmfuncw.r.t. different groups in a dict format, where keys corresponding togroup_keywhile values should be a dict for regression algorithm parameter value assignments.An example is as follows:
Valid only when
massiveis True and defaults to None.- pivotedbool, optional
If True, it will enable PAL unified regression for pivoted data. In this case, meta data must be provided in the fit function.
Defaults to False.
- **kwargskeyword arguments
Arbitrary keyword arguments and please referred to the responding algorithm for the parameters' key-value pair.
Note that some parameters are disabled/modified in the regression algorithm!
'DecisionTree' :
DecisionTreeRegressorDisabled parameters:
output_rulesParameters removed from initialization but can be specified in fit():
categorical_variable
'HybridGradientBoostingTree' :
HybridGradientBoostingRegressorDisabled parameters:
calculate_importanceParameters removed from initialization but can be specified in fit():
categorical_variableModified parameters:
obj_funcadded 'quantile' as a new choice. This is for quantile regression. In particular, only under 'quantile' loss can interval prediction be made for HGBT model in predict/score phase.
'LinearRegression' :
LinearRegressionDisabled parameters: pmml_export
Parameters removed from initialization but can be specified in fit(): categorical_variable
Parameters with changed meaning :
json_export, where False value now means 'Exports multiple linear regression model in PMML'.
'RandomDecisionTree' :
RDTRegressorDisabled parameters:
calculate_oobParameters removed from initialization but can be specified in fit():
categorical_variable
'MLP' :
MLPRegressorDisabled parameters:
functionalityParameters removed from initialization but can be specified in fit():
categorical_variable
'SVM' :
SVRParameters removed from initialization but can be specified in fit():
categorical_variable
'GLM' :
GLMDisabled parameters:
output_fittedParameters removed from initialization but can be specified in fit():
categorical_variable
'GeometricRegression' :
BiVariateGeometricRegressionDisabled parameters:
pmml_export
'PolynomialRegression' :
PolynomialRegressionDisabled parameters:
pmml_export
'ExponentialRegression' :
ExponentialRegressionDisabled parameters:
pmml_export
'LogarithmicRegression' :
BiVariateNaturalLogarithmicRegressionDisabled parameters:
pmml_export
For more parameter mappings of hana_ml and HANA PAL, please refer to the doc page: Parameter Mappings.
Examples
Case 1: Training data for regression:
>>> data_tbl.collect() ID X1 X2 X3 Y 0 0 0.00 A 1 -6.879 1 1 0.50 A 1 -3.449 2 2 0.54 B 1 6.635 3 3 1.04 B 1 11.844 4 4 1.50 A 1 2.786 5 5 0.04 B 2 2.389 6 6 2.00 A 2 -0.011 7 7 2.04 B 2 8.839 8 8 1.54 B 1 4.689 9 9 1.00 A 2 -5.507
Create an UnifiedRegression instance for linear regression problem:
>>> mlr_params = dict(solver = 'qr', adjusted_r2=False, thread_ratio=0.5)
>>> umlr = UnifiedRegression(func='LinearRegression', **mlr_params)
Fit the UnifiedRegression instance with the aforementioned training data:
>>> par_params = dict(partition_method='random', training_percent=0.7, partition_random_state=2, output_partition_result=True)
>>> umlr.fit(data = data_tbl, key = 'ID', label = 'Y', **par_params)
Check the resulting statistics on testing data:
>>> umlr.statistics_.collect() STAT_NAME STAT_VALUE 0 TEST_EVAR 0.871459247598903 1 TEST_MAE 2.0088082000000003 2 TEST_MAPE 12.260003987804756 3 TEST_MAX_ERROR 5.329849599999999 4 TEST_MSE 9.551661310681718 5 TEST_R2 0.7774293644548433 6 TEST_RMSE 3.09057621013974 7 TEST_WMAPE 0.7188006440839695
Data for prediction:
>>> data_pred.collect() ID X1 X2 X3 0 0 1.690 B 1 1 1 0.054 B 2 2 2 980.123 A 2 3 3 1.000 A 1 4 4 0.563 A 1
Perform prediction:
>>> pred_res = mlr.predict(data = data_pred, key = 'ID') >>> pred_res.collect() ID SCORE UPPER_BOUND LOWER_BOUND REASON 0 0 8.719607 None None None 1 1 1.416343 None None None 2 2 3318.371440 None None None 3 3 -2.050390 None None None 4 4 -3.533135 None None None
Data for scoring:
>>> data_score.collect() ID X1 X2 X3 Y 0 0 1.690 B 1 1.2 1 1 0.054 B 2 2.1 2 2 980.123 A 2 2.4 3 3 1.000 A 1 1.8 4 4 0.563 A 1 1.0
Perform scoring:
>>> score_res = umlr.score(data = data_score, key = "ID", label = 'Y')
Check the statistics on scoring data:
>>> score_res[1].collect() STAT_NAME STAT_VALUE 0 EVAR -6284768.906191169 1 MAE 666.5116459919999 2 MAPE 278.9837795885635 3 MAX_ERROR 3315.9714402299996 4 MSE 2199151.795823181 5 R2 -7854112.55651136 6 RMSE 1482.9537402842952 7 WMAPE 392.0656741129411
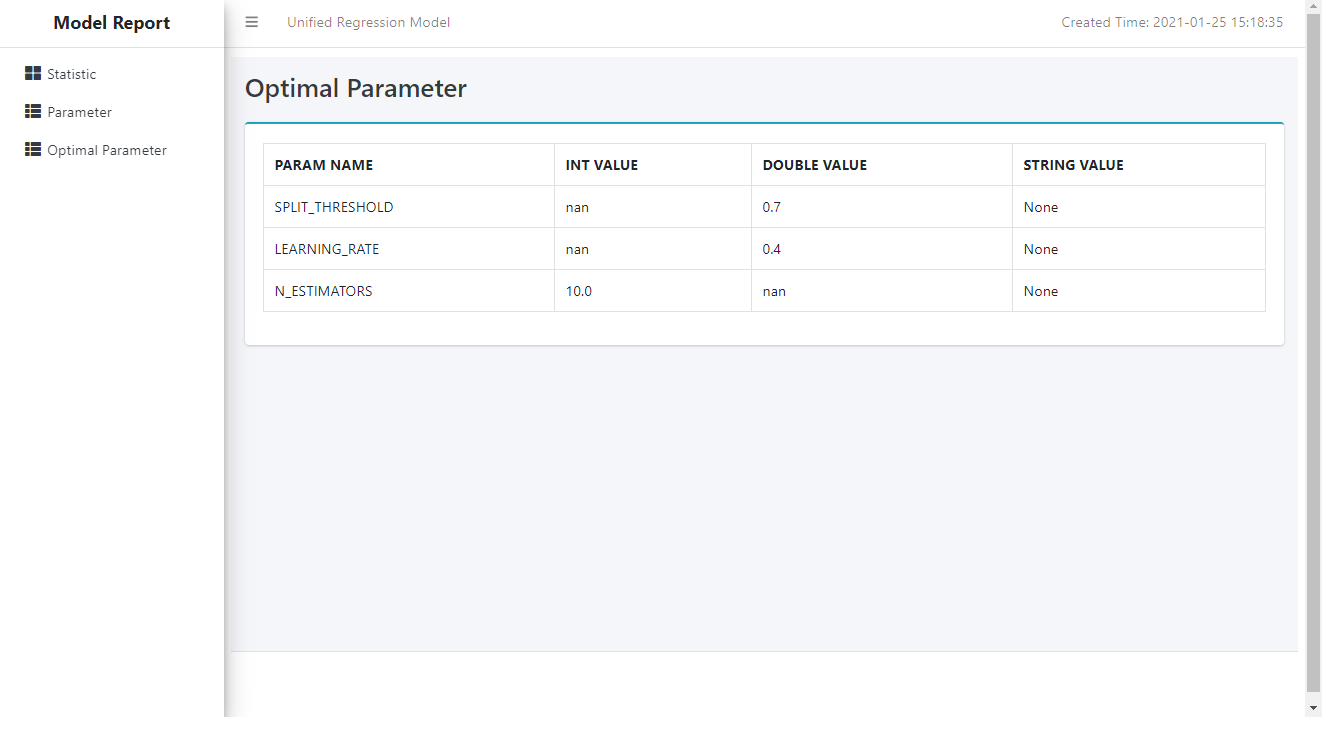
Case 2: UnifiedReport for UnifiedRegression is shown as follows:
>>> hgr = UnifiedRegression(func = 'HybridGradientBoostingTree') >>> gscv = GridSearchCV(estimator=hgr, param_grid={'learning_rate': [0.1, 0.4, 0.7, 1], 'n_estimators': [4, 6, 8, 10], 'split_threshold': [0.1, 0.4, 0.7, 1]}, train_control=dict(fold_num=5, resampling_method='cv', random_state=1), scoring='rmse') >>> gscv.fit(data=diabetes_train, key= 'ID', label='CLASS', partition_method='random', partition_random_state=1, build_report=True)
To see the model report:
>>> UnifiedReport(gscv.estimator).display()
Case 3: Local interpretability of models - linear SHAP
>>> umlr = UnifiedRegression(func='LinearRegression') >>> umlr.fit(data=df_train, background_size=4)#specify positive background data size to activate local interpretability >>> res = umlr.predict(data=df_predict, ... ..., ... top_k_attributions=5, ... sample_size=0, ... random_state=2022, ... ignore_correlation=False)#consider correlations between features, only for linear SHAP
Case 4: Local interpretability of models - tree SHAP for tree model
>>> udtr = UnifiedRegression(func='DecisionTree') >>> udtr.fit(data=df_train) >>> res = udtr.predict(data=df_predict, ... ..., ... top_k_attributions=8, ... attribution_method='tree-shap',#specify attribution method to activate local interpretability ... random_state=2022)
Case 5: Local interpretability of models - kernel SHAP for non-linear/non-tree models
>>> usvr = UnifiedRegression(func='SVM')# SVM model >>> usvr.fit(data=df_train, background_size=8)#specify positive background data size to activate local interpretability >>> res = usvr.predict(data=df_predict, ... ..., ... top_k_attributions=6, ... sample_size=6, ... random_state=2022)
- Attributes:
- model_DataFrame
Model content.
- statistics_DataFrame
Names and values of statistics.
- optimal_param_DataFrame
Provides optimal parameters selected.
Available only when parameter selection is triggered.
- partition_DataFrame
Partition result of training data.
Available only when training data has an ID column and random partition is applied.
- error_msg_DataFrame
Error message. Only valid if
massiveis True when initializing an 'UnifiedRegression' instance.
Methods
Build the model report.
create_model_state([model, function, ...])Create PAL model state.
delete_model_state([state])Delete PAL model state.
It will disable mlflow autologging.
enable_mlflow_autologging([schema, meta, ...])It will enable mlflow autologging.
fit(data[, key, features, label, purpose, ...])Fit function for unified regression.
generate_html_report(filename)Save model report as a html file.
Render model report as a notebook iframe.
Returns the feature importances
Returns the optimal parameters.
Returns the performance metrics.
predict(data[, key, features, model, ...])Predict with the regression model.
score(data[, key, features, label, model, ...])Users can use the score function to evaluate the model quality.
set_framework_version(framework_version)Switch v1/v2 version of report.
set_model_state(state)Set the model state by state information.
Use the reason code generated during the prediction phase to build a ShapleyExplainer instance.
set_shapley_explainer_of_score_phase(...[, ...])Use the reason code generated during the scoring phase to build a ShapleyExplainer instance.
update_cv_params(name, value, typ)Update parameters for model-evaluation/parameter-selection.
- disable_mlflow_autologging()
It will disable mlflow autologging.
- enable_mlflow_autologging(schema=None, meta=None, is_exported=False, registered_model_name=None)
It will enable mlflow autologging.
- Parameters:
- schemastr, optional
Define the model storage schema for mlflow autologging.
Defaults to the current schema.
- metastr, optional
Define the model storage meta table for mlflow autologging.
Defaults to 'HANAML_MLFLOW_MODEL_STORAGE'.
- is_exportedbool, optional
Determine whether export the HANA model to mlflow.
Defaults to False.
- registered_model_namestr, optional
MLFlow registered_model_name.
- update_cv_params(name, value, typ)
Update parameters for model-evaluation/parameter-selection.
- fit(data, key=None, features=None, label=None, purpose=None, partition_method=None, partition_random_state=None, training_percent=None, output_partition_result=None, categorical_variable=None, background_size=None, background_random_state=None, build_report=False, impute=False, strategy=None, strategy_by_col=None, als_factors=None, als_lambda=None, als_maxit=None, als_randomstate=None, als_exit_threshold=None, als_exit_interval=None, als_linsolver=None, als_cg_maxit=None, als_centering=None, als_scaling=None, group_key=None, group_params=None, output_coefcov=None, output_leaf_values=None, meta_data=None, significance_level=None)
Fit function for unified regression.
- Parameters:
- dataDataFrame
DataFrame containing the training data.
If the corresponding UnifiedRegression instance is for pivoted input data(i.e. setting
pivoted= True in initialization), thendatamust be pivoted such that:in massive mode,
datamust be exactly structured as follows:1st column: Group ID, type INTEGER, VARCHAR or NVARCHAR
2nd column: Record ID, type INTEGER, VARCHAR or NVARCHAR
3rd column: Variable Name, type VARCHAR or NVARCHAR
4th column: Variable Value, type VARCHAR or NVARCHAR
5th column: Self-defined Data Partition, type INTEGER, 1 for training and 2 for validation.
in non-massive mode,
datamust be exactly structured as follows:1st column: Record ID, type INTEGER, VARCHAR or NVARCHAR
2nd column: Variable Name, type VARCHAR or NVARCHAR
3rd column: Variable Value, type VARCHAR or NVARCHAR
4th column: Self-defined Data Partition, type INTEGER, 1 for training and 2 for validation.
Note
If
datais pivoted, then the following parameters become ineffective:key,features,label,group_keyandpurpose.- keystr, optional
Name of ID column.
In single mode, if
keyis not provided, then: ifdatais indexed by a single column, thenkeydefaults to that index column; Otherwise, it is assumed thatdatacontains no ID column.In massive mode, defaults to the first-non group key column of data if the index columns of data is not provided. Otherwise, defaults to the second of index columns of data and the first column of index columns is group_key.
- featureslist of str, optional
Names of the feature columns.
If
featuresis not provided, it defaults to all non-key, non-label columns.- labelstr or list of str, optional
Name of the dependent variable.
Should be a list of two strings for GLM models with
familybeing 'binomial'.If
labelis not provided, it defaults to:the first non-key column of
data, whenfuncparameter from initialization function takes the following values:'GeometricRegression', 'PolynomialRegression', 'LinearRegression', 'ExponentialRegression', 'GLM' (except whenfamilyis 'binomial')the first two non-key columns of
data, whenfuncparameter in initialization function takes the value of 'GLM' andfamillyis specified as 'binomial'.
- purposestr, optional
Indicates the name of purpose column which is used for predefined data partition.
The meaning of value in the column for each data instance is shown below:
1 : training.
2 : testing.
Mandatory and valid only when
partition_methodis 'predefined'..- partition_method{'no', 'predefined', 'random'}, optional
Defines the way to divide the dataset.
'no' : no partition.
'predefined' : predefined partition.
'random' : random partition.
Defaults to 'no'.
- partition_random_stateint, optional
Indicates the seed used to initialize the random number generator for data partition.
Valid only when
partition_methodis set to 'random'.0 : Uses the system time.
Not 0 : Uses the specified seed.
Defaults to 0.
- training_percentfloat, optional
The percentage of data used for training.
Value range: 0 <= value <= 1.
Defaults to 0.8.
- output_partition_resultbool, optional
Specifies whether or not to output the partition result of
datain data partition table.Valid only when
keyis provided andpartition_methodis set to 'random'.Defaults to False.
- categorical_variablestr or list of str, optional
Specifies INTEGER column(s) that should be treated as categorical.
Other INTEGER columns will be treated as continuous.
No default value.
- background_sizeint, optional
Specifies the size of background data used for Shapley Additive Explanations (SHAP) values calculation.
Should not larger than the size of training data.
Valid only for Exponential Regression, Generalized Linear Models(GLM), Linear Regression, Multi-layer Perceptron and Support Vector Regression.
Defaults to 0(no background data, in which case the calculation of SHAP values shall be disabled).
- background_random_stateint, optional
Specifies the seed for random number generator in the background data sampling.
0 : Uses current time as seed
Others : The specified seed value
Valid only for Exponential Regression, Generalized Linear Models(GLM), Linear Regression, Multi-layer Perceptron and Support Vector Regression(SVR).
Defaults to 0.
- build_reportbool, optional
Whether to build a model report or not.
Example:
>>> from hana_ml.visualizers.unified_report import UnifiedReport >>> hgr = UnifiedRegression(func='HybridGradientBoostingTree') >>> hgr.fit(data=df_boston, key= 'ID', label='MEDV', build_report=True) >>> UnifiedReport(hgr).display()
Defaults to False.
- imputebool, optional
Specifies whether or not to impute missing values in the training data.
Defaults to False.
- strategy, strategy_by_col, als_*parameters for missing value handling, optional
All these parameters mentioned above are for handling missing values in data, please see Parameters for Missing Value Handling in HANA DataFrame for more details.
All parameters are valid only when
imputeis set as True.- group_keystr, optional
The column of group_key. Data type can be INT or NVARCHAR/VARCHAR. If data type INT, only parameters set in the group_params are valid.
This parameter is only valid when
massiveis set as True in class instance initialization.Defaults to the first column of data if the index columns of data is not provided. Otherwise, defaults to the first column of index columns.
- group_paramsdict, optional
If massive mode is activated (
massiveis set as True in class instance initialization), input data for regression shall be divided into different groups with different regression parameters applied. This parameter specifies the parameter values of the chosen regression algorithmfuncw.r.t. different groups in a dict format, where keys corresponding togroup_keywhile values should be a dict for regression algorithm parameter value assignments.An example is as follows:
Valid only when
massiveis set as True in class instance initialization.Defaults to None.
- output_coefcovbool, optional
Specifies whether or not to output coefficient covariance information for Linear Regression.
Valid only if
funcis specified as 'LinearRegression' andjson_exportas True.Defaults to False.
Note
To enable output of confidence/prediction interval for Linear Regression model in UnifiedRegression during predicting/scoring phase, we need to set
output_coefcovas 1.- output_leaf_valuesbool, optional
Specifies whether or not save the target target values in each leaf node in the training phase for Random Decision Trees model(otherwise only mean of the target values is saved in the model). Setting the value of this parameter as True to enable the output of prediction interval for Random Decision Trees model in UnifiedRegression during predicting/scoring phase
Valid only for fitting Random Decision Trees model(i.e. setting
funcas 'RandomDecisionTree') whenmodel_formatis 'json' orcompressionis True during class instance initialization.Defaults to False.
- meta_dataDataFrame, optional
Specifies the meta data for pivoted input data. Mandatory if
pivotedis specified as True in initializing the class instance.If provided, then
meta_datashould be structured as follows:1st column: NAME, type VRACHAR or NVARCHAR. The name of the variable.
2nd column: TYPE, VRACHAR or NVARCHAR. The type of the variable, can be CONTINUOUS, CATEGORICAL or TARGET.
- significance_levelfloat, optional
Specifies the significance level of the prediction interval for Hybrid Gradient Boosting Tree(HGBT) model.
Valid only when
funcis specified as 'HybridGradientBoostingTree', andobj_funcas 'quantile' during class instance initialization.Defaults to 0.05.
- Returns:
- A fitted object of 'UnifiedRegression'.
- get_optimal_parameters()
Returns the optimal parameters.
- get_performance_metrics()
Returns the performance metrics.
- get_feature_importances()
Returns the feature importances
- predict(data, key=None, features=None, model=None, thread_ratio=None, prediction_type=None, significance_level=None, handle_missing=None, block_size=None, top_k_attributions=None, attribution_method=None, sample_size=None, random_state=None, ignore_correlation=None, impute=False, strategy=None, strategy_by_col=None, als_factors=None, als_lambda=None, als_maxit=None, als_randomstate=None, als_exit_threshold=None, als_exit_interval=None, als_linsolver=None, als_cg_maxit=None, als_centering=None, als_scaling=None, group_key=None, group_params=None, interval_type=None)
Predict with the regression model.
- Parameters:
- dataDataFrame
Data to be predicted.
If self.pivoted is True, then
datamust be pivoted, indicating that it should be structured the same as the pivoted data used for training(exclusive of the last data partition column) and contains no target values. In this case, the following parameters become ineffective:key,features,group_key.- keystr, optional
Name of ID column.
In single mode, mandatory if
datais not indexed, or the index ofdatacontains multiple columns. Defaults to the single index column ofdataif not provided.In massive mode, defaults to the first-non group key column of data if the index columns of data is not provided. Otherwise, defaults to the second of index columns of data and the first column of index columns is group_key.
- featuresa list of str, optional
Names of feature columns in data for prediction.
Defaults all non-ID columns in data if not provided.
- modelDataFrame
Fitted regression model.
Defaults to self.model_.
- thread_ratiofloat, optional
Controls the proportion of available threads to use for prediction.
The value range is from 0 to 1, where 0 indicates a single thread, and 1 indicates up to all available threads.
Values between 0 and 1 will use that percentage of available threads.
Values outside this range tell PAL to heuristically determine the number of threads to use.
Defaults to the PAL's default value.
- prediction_typestr, optional
Specifies the type of prediction. Valid options include:
'response' : direct response (with link)
'link' : linear response (without link)
Valid only for GLM models.
Defaults to 'response'.
- significance_levelfloat, optional
Specifies significance level for the confidence/prediction interval.
Valid only for the following 3 cases:
GLM model with IRLS solver applied(i.e.
funcis specified as 'GLM' andsolveras 'irls' during class instance initialization).Linear Regression model with json model imported(i.e.
funcis specified as 'LinearRegression' andjson_exportas True during class instance initialization).
Defaults to 0.05.
- handle_missingstr, optional
Specifies the way to handle missing values. Valid options include:
'skip' : skip(i.e. remove) rows with missing values
'fill_zero' : replace missing values with 0.
Valid only for GLM models.
Defaults to 'fill_zero'.
- block_sizeint, optional
Specifies the number of data loaded per time during scoring.
0: load all data once
Others: the specified number
This parameter is for reducing memory consumption, especially as the predict data is huge, or it consists of a large number of missing independent variables. However, you might lose some efficiency.
Valid only for RandomDecisionTree(RDT) models.
Defaults to 0.
- top_k_attributionsint, optional
Specifies the number of features with highest attributions to output.
Defaults to 10.
- attribution_method{'no', 'saabas', 'tree-shap'}, optional
Specifies which method to use for model reasoning.
'no' : No reasoning
'saabas' : Saabas method
'tree-shap' : Tree SHAP method
Valid only for tree-based models, i.e. DecisionTree, RandomDecisionTree and HybridGradientBoostingTree models.
Defaults to 'tree-shap'.
- sample_sizeint, optional
Specifies the number of sampled combinations of features.
0 : Heuristically determined by algorithm
Others : The specified sample size
Valid only for Exponential Regression, GLM, Linear Regression, MLP and Support Vector Regression.
Defaults to 0.
- random_stateint, optional
Specifies the seed for random number generator when sampling the combination of features.
0 : User current time as seed
Others : The actual seed
Valid only for Exponential Regression, GLM, Linear Regression, MLP and Support Vector Regression.
Defaults to 0.
- ignore_correlationbool, optional
Specifies whether or not to ignore the correlation between the features.
Valid only for Exponential Regression, GLM and Linear Regression that adopt linear SHAP for local interpretability of models.
Defaults to False.
- imputebool, optional
Specifies whether or not to impute missing values in
data.Defaults to False.
- strategy, strategy_by_col, als_*parameters for missing value handling, optional
All these parameters mentioned above are for handling missing values in data, please see Parameters for Missing Value Handling in HANA DataFrame for more details.
All parameters are valid only when
imputeis set as True.- group_keystr, optional
The column of group_key. Data type can be INT or NVARCHAR/VARCHAR. If data type is INT, only parameters set in the group_params are valid.
This parameter is only valid when
massiveis set as True in class instance initialization.Defaults to the first column of data if the index columns of data is not provided. Otherwise, defaults to the first column of index columns.
- group_paramsdict, optional
If massive mode is activated (
massiveis set as True in class instance initialization), input data for regression shall be divided into different groups with different regression parameters applied. This parameter specifies the parameter values of the chosen regression algorithmfuncw.r.t. different groups in a dict format, where keys corresponding togroup_keywhile values should be a dict for regression algorithm parameter value assignments.An example is as follows:
Valid only when
massiveis set as True in class instance initialization.Defaults to None.
- interval_type{'no', 'confidence', 'prediction'}, optional
Specifies the type of interval to output:
'no': do not calculate and output any interval
'confidence': calculate and output the confidence interval
'prediction': calculate and output the prediction interval
Valid only for one of the following 4 cases:
GLM model with IRLS solver applied(i.e.
funcis specified as 'GLM' andsolveras 'irls' during class instance initialization).Linear Regression model with json model imported and coefficient covariance information computed (i.e.
funcis specified as 'LinearRegression',json_exportspecified as True during class instance initialization, andoutput_coefcovspecified as True during the training phase).Random Decision Trees model with all leaf values retained(i.e.
funcis 'RandomDecisionTree' andoutput_leaf_valuesis True). In this case,interval_typecould be specified as either 'no' or 'prediction'.Hybrid Gradient Boosting Tree model with quantile objective function(i.e.
funcis 'HybridGradientBoostingTree', andobj_funcis 'quantile' for class instance initialization). In this case,interval_typecan be specified as either 'no' or 'prediction'.
Defaults to 'no'.
- Returns:
- DataFrame
A collection of DataFrames listed as follows:
Prediction result by ignoring the true labels of the input data, structured the same as the result table of predict() function.
Error message (optional). Only valid if
massiveis True when initializing an 'UnifiedRegression' instance.
Examples
Example 1 - Linear Regression predict with confidence interval:
>>> bsh_train = conn.table('BOSTON_HOUSING_TRAIN_DATA') >>> bsh_test = conn.table('BOSTON_HOUSING_TEST_DATA') >>> ulr = UnifiedRegression(func='LinearRegression', ... json_export=True)# prediction/confidence interval only available for json model >>> ulr.fit(data=bsh_df, ... key='ID', ... label='MEDV', ... output_coefcov=True)# set as True to output coefficient interval >>> ulr.predict(data=bsh_test.deselect('MEDV'), ... key='ID', ... significance_level=0.05, ... interval_type='confidence')# specifies the interval type as confidence
Example 2 - GLM model predict of response with prediction interval:
>>> bsh_train = conn.table('BOSTON_HOUSING_TRAIN_DATA') >>> bsh_test = conn.table('BOSTON_HOUSING_TEST_DATA') >>> uglm = UnifiedRegression(func='GLM', family='gaussian', link='identity') >>> uglm.fit(data=bsh_df, key='ID', label='MEDV') >>> ulr.predict(data=bsh_test.deselect('MEDV'), ... key='ID', ... significance_level=0.05, ... prediction_type='response',# set to 'response' for direct response ... interval_type='prediction')# specifies the interval type as prediction
- score(data, key=None, features=None, label=None, model=None, prediction_type=None, significance_level=None, handle_missing=None, thread_ratio=None, block_size=None, top_k_attributions=None, attribution_method=None, sample_size=None, random_state=None, ignore_correlation=None, impute=False, strategy=None, strategy_by_col=None, als_factors=None, als_lambda=None, als_maxit=None, als_randomstate=None, als_exit_threshold=None, als_exit_interval=None, als_linsolver=None, als_cg_maxit=None, als_centering=None, als_scaling=None, group_key=None, group_params=None, interval_type=None)
Users can use the score function to evaluate the model quality. In the Unified regression, statistics and metrics are provided to show the model quality.
- Parameters:
- dataDataFrame
Data for scoring.
If self.pivoted is True, then
datamust be pivoted, indicating that it should be structured the same as the pivoted data used for training(exclusive of the last data partition column). In this case, the following parameters become ineffective:key,features,label,group_key.- keystr, optional
Name of the ID column.
In single mode, mandatory if
datais not indexed, or the index ofdatacontains multiple columns. Defaults to the single index column ofdataif not provided.In massive mode, defaults to the first-non group key column of data if the index columns of data is not provided. Otherwise, defaults to the second of index columns of data and the first column of index columns is group_key.
- featuresListOfString or str, optional
Names of feature columns.
Defaults to all non-ID, non-label columns if not provided.
- labelstr, optional
Name of the label column.
Defaults to the last non-ID column if not provided.
- modelDataFrame
Fitted regression model.
Defaults to self.model_.
- thread_ratiofloat, optional
Controls the proportion of available threads to use for prediction.
The value range is from 0 to 1, where 0 indicates a single thread, and 1 indicates up to all available threads.
Values between 0 and 1 will use that percentage of available threads.
Values outside this range tell PAL to heuristically determine the number of threads to use.
Defaults to the PAL's default value.
- prediction_typestr, optional
Specifies the type of prediction. Valid options include:
'response' : direct response (with link).
'link' : linear response (without link).
Valid only for GLM models.
Defaults to 'response'.
- significance_levelfloat, optional
Specifies significance level for the confidence interval and prediction interval.
Valid only for the following 2 cases:
GLM model with IRLS solver applied(i.e.
funcis specified as 'GLM' andsolveras 'irls' during class instance initialization).Linear Regression model with json model imported(i.e.
funcis specified as 'LinearRegression' andjson_exportas True during class instance initialization).
Defaults to 0.05.
- handle_missingstr, optional
Specifies the way to handle missing values. Valid options include:
'skip' : skip rows with missing values.
'fill_zero' : replace missing values with 0.
Valid only for GLM models.
Defaults to 'fill_zero'.
- block_sizeint, optional
Specifies the number of data loaded per time during scoring.
0: load all data once.
Others: the specified number.
This parameter is for reducing memory consumption, especially as the predict data is huge, or it consists of a large number of missing independent variables. However, you might lose some efficiency.
Valid only for RandomDecisionTree models.
Defaults to 0.
- top_k_attributionsint, optional
Specifies the number of features with highest attributions to output.
Defaults to 10.
- attribution_method{'no', 'saabas', 'tree-shap'}, optional
Specifies which method to use for model reasoning.
'no' : No reasoning.
'saabas' : Saabas method.
'tree-shap' : Tree SHAP method.
Valid only for tree-based models, i.e. DecisionTree, RandomDecisionTree and HybridGradientBoostingTree models.
Defaults to 'tree-shap'.
- sample_sizeint, optional
Specifies the number of sampled combinations of features.
0 : Heuristically determined by algorithm.
Others : The specified sample size.
Valid only for Exponential Regression, GLM, Linear Regression, MLP and Support Vector Regression.
Defaults to 0.
- random_stateint, optional
Specifies the seed for random number generator when sampling the combination of features.
0 : User current time as seed.
Others : The actual seed.
Valid only for Exponential Regression, GLM, Linear Regression, MLP and Support Vector Regression.
Defaults to 0.
- ignore_correlationbool, optional
Specifies whether or not to ignore the correlation between the features.
Valid only for Exponential Regression, GLM and Linear Regression.
Defaults to False.
- imputebool, optional
Specifies whether or not to impute missing values in
data.Defaults to False.
- strategy, strategy_by_col, als_*parameters for missing value handling, optional
All these parameters mentioned above are for handling missing values in data, please see Parameters for Missing Value Handling in HANA DataFrame for more details.
All parameters are valid only when
imputeis set as True.- group_keystr, optional
The column of group_key. Data type can be INT or NVARCHAR/VARCHAR. If data type is INT, only parameters set in the group_params are valid.
This parameter is only valid when
massiveis set as True in class instance initialization.Defaults to the first column of data if the index columns of data is not provided. Otherwise, defaults to the first column of index columns.
- group_paramsdict, optional
If massive mode is activated (
massiveis set as True in class instance initialization), input data for regression shall be divided into different groups with different regression parameters applied. This parameter specifies the parameter values of the chosen regression algorithmfuncw.r.t. different groups in a dict format, where keys corresponding togroup_keywhile values should be a dict for regression algorithm parameter value assignments.An example is as follows:
Valid only when
massiveis set True in class instance initialization.Defaults to None.
- interval_type{'no', 'confidence', 'prediction'}, optional
Specifies the type of interval to output:
'no': do not calculate and output any interval.
'confidence': calculate and output the confidence interval.
'prediction': calculate and output the prediction interval.
Valid only for one of the following 4 cases:
GLM model with IRLS solver applied(i.e.
funcis specified as 'GLM' andsolveras 'irls' during class instance initialization).Linear Regression model with json model imported and coefficient covariance information computed (i.e.
funcis specified as 'LinearRegression',json_exportspecified as True during class instance initialization, andoutput_coefcovspecified as True during the training phase).Random Decision Trees model with all leaf values retained(i.e.
funcis 'RandomDecisionTree' andoutput_leaf_valuesis True). In this case,interval_typecould be specified as either 'no' or 'prediction'.Hybrid Gradient Boosting Tree model with quantile objective function(i.e.
funcis 'HybridGradientBoostingTree', andobj_funcis 'quantile' for class instance initialization). In this case,interval_typecan be specified as either 'no' or 'prediction'.
Defaults to 'no'.
- Returns:
- DataFrame
A collection of DataFrames listed as follows:
Prediction result by ignoring the true labels of the input data, structured the same as the result table of predict() function.
Statistics results
Error message (optional). Only valid if
massiveis True when initializing an 'UnifiedRegression' instance.
Examples
Example 1 - Linear Regression scoring with prediction interval:
>>> bsh_train = conn.table('BOSTON_HOUSING_TRAIN_DATA') >>> bsh_test = conn.table('BOSTON_HOUSING_TEST_DATA') >>> ulr = UnifiedRegression(func='LinearRegression', ... json_export=True)# prediction/confidence interval only available for json model >>> ulr.fit(data=bsh_df, ... key='ID', ... label='MEDV', ... output_coefcov=True) # set as True to output interval >>> ulr.predict(data=bsh_test.deselect('MEDV'), ... key='ID', ... significance_level=0.05, ... interval_type='prediction')# specifies the interval type as prediction
Example 2 - GLM model predict of linear response with confidence interval:
>>> bsh_train = conn.table('BOSTON_HOUSING_TRAIN_DATA') >>> bsh_test = conn.table('BOSTON_HOUSING_TEST_DATA') >>> uglm = UnifiedRegression(func='GLM', family='gaussian', link='identity') >>> uglm.fit(data=bsh_df, key='ID', label='MEDV') >>> ulr.predict(data=bsh_test.deselect('MEDV'), ... key='ID', ... significance_level=0.05, ... prediction_type='link', # set as 'link' for linear response ... interval_type='confidence')# specifies the interval type as confidence
- build_report()
Build the model report.
Examples
>>> from hana_ml.visualizers.unified_report import UnifiedReport >>> hgr = UnifiedRegression(func='HybridGradientBoostingTree') >>> hgr.fit(data=df_boston, key= 'ID', label='MEDV') >>> hgr.build_report() >>> UnifiedReport(hgr).display()
- create_model_state(model=None, function=None, pal_funcname='PAL_UNIFIED_REGRESSION', state_description=None, force=False)
Create PAL model state.
- Parameters:
- modelDataFrame, optional
Specify the model for AFL state.
Defaults to self.model_.
- functionstr, optional
Specify the function name of the regression algorithm.
Valid options include:
'SVM' : Support Vector Regression
'MLP' : Multilayer Perceptron Regression
'DT' : Decision Tree Regression
'HGBT' : Hybrid Gradient Boosting Tree Regression
'MLR' : Multiple Linear Regression
'RDT' : Random Decision Trees Regression
Defaults to self.real_func.
Note
The default value could be invalid. In such case, a ValueError shall be thrown.
- pal_funcnameint or str, optional
PAL function name.
Defaults to 'PAL_UNIFIED_REGRESSION'.
- state_descriptionstr, optional
Description of the state as model container.
Defaults to None.
- forcebool, optional
If True it will delete the existing state.
Defaults to False.
- set_model_state(state)
Set the model state by state information.
- Parameters:
- state: DataFrame or dict
If state is DataFrame, it has the following structure:
NAME: VARCHAR(100), it mush have STATE_ID, HINT, HOST and PORT.
VALUE: VARCHAR(1000), the values according to NAME.
If state is dict, the key must have STATE_ID, HINT, HOST and PORT.
- delete_model_state(state=None)
Delete PAL model state.
- Parameters:
- stateDataFrame, optional
Specified the state.
Defaults to self.state.
- property fit_hdbprocedure
Returns the generated hdbprocedure for fit.
- generate_html_report(filename)
Save model report as a html file.
- Parameters:
- filenamestr
Html file name.
- generate_notebook_iframe_report()
Render model report as a notebook iframe.
- property predict_hdbprocedure
Returns the generated hdbprocedure for predict.
- set_framework_version(framework_version)
Switch v1/v2 version of report.
- Parameters:
- framework_version{'v2', 'v1'}, optional
v2: using report builder framework. v1: using pure html template.
Defaults to 'v2'.
- set_shapley_explainer_of_predict_phase(shapley_explainer, display_force_plot=True)
Use the reason code generated during the prediction phase to build a ShapleyExplainer instance.
When this instance is passed in, the execution results of this instance will be included in the report of v2 version.
- Parameters:
- shapley_explainer
ShapleyExplainer ShapleyExplainer instance.
- display_force_plotbool, optional
Whether to display the force plot.
Defaults to True.
- shapley_explainer
- set_shapley_explainer_of_score_phase(shapley_explainer, display_force_plot=True)
Use the reason code generated during the scoring phase to build a ShapleyExplainer instance.
When this instance is passed in, the execution results of this instance will be included in the report of v2 version.
- Parameters:
- shapley_explainer
ShapleyExplainer ShapleyExplainer instance.
- display_force_plotbool, optional
Whether to display the force plot.
Defaults to True.
- shapley_explainer
Inherited Methods from PALBase
Besides those methods mentioned above, the UnifiedRegression class also inherits methods from PALBase class, please refer to PAL Base for more details.