Genetic Optimization in AutoML
Currently the auto_ml module(inclusive of AutomaticClassification, AutomaticRegression and AutomaticTimeSeries) in hana_ml.algorithms.pal package uses genetic algorithm(GA) for pipeline optimization, in which NSGA-II is used as selection algorithm to support multiple objectives.
In general, the evolution of genetic optimization is an iterative process, with the population in each iteration called a generation. It usually starts from a population of randomly generated individuals, the fitness of every individual in the population is then evaluated (the fitness is usually the value of the objective function in the optimization problem being solved). The better fitted individuals are stochastically selected from the current population, and each individual's genome is modified (recombined and possibly randomly mutated) to form a new generation. The new generation of candidates(individuals) is then used in the next iteration of the algorithm, and it repeats until either the maximum number of generations has been reached for the current population, or a satisfying fitness level has been reached.
Individual Representation
In the auto_ml module of hana_ml.algorithms.pal package, each individual is nothing but a chain of operators that form a pipeline. In GA, any such individual is represented by a latent tree structure, illustrated as follows:
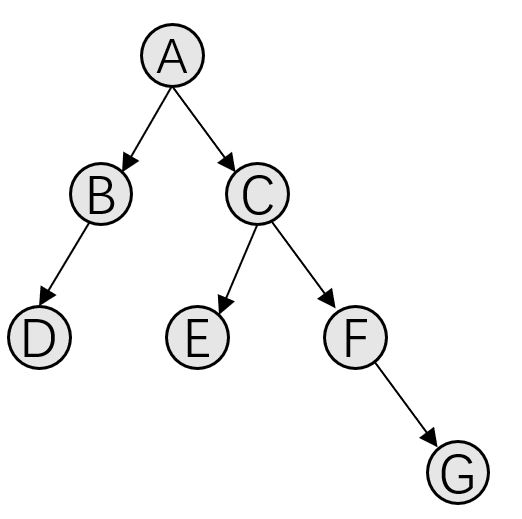
By specifying the maximum and minimum number of layers of the tree structure, GA can randomly generate individuals that fullfill the condition specified by the given config dictionary.
Selection
Selection is a process whereby certain individuals from the current generation are selected as parents of the next generation. Currently the selection algorithm is NSGA-II.
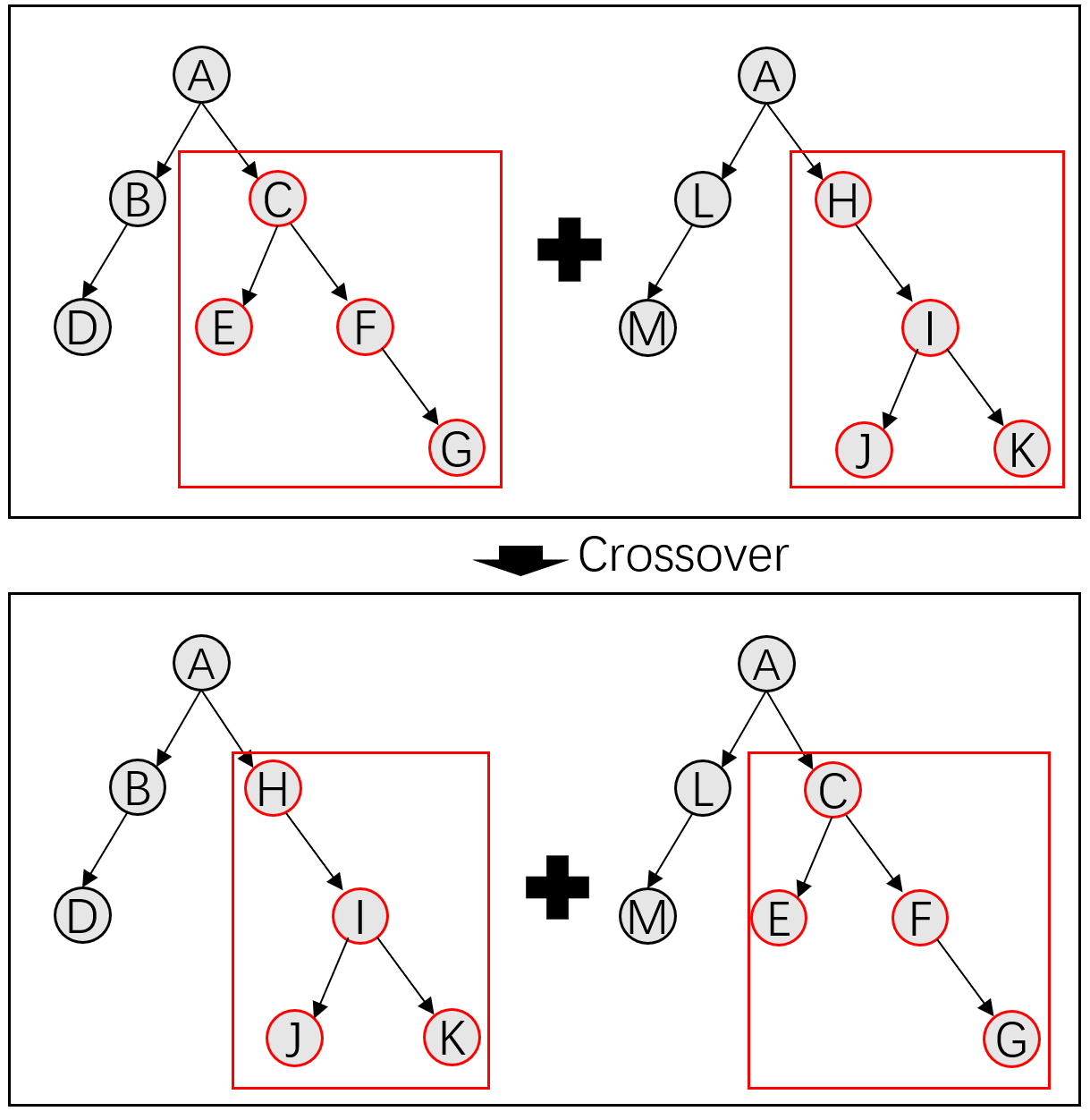
Crossover
For two selected individuals, randomly exchange a pair of leaf nodes of equal type but different values, or a pair of child nodes with different structures.
Mutation
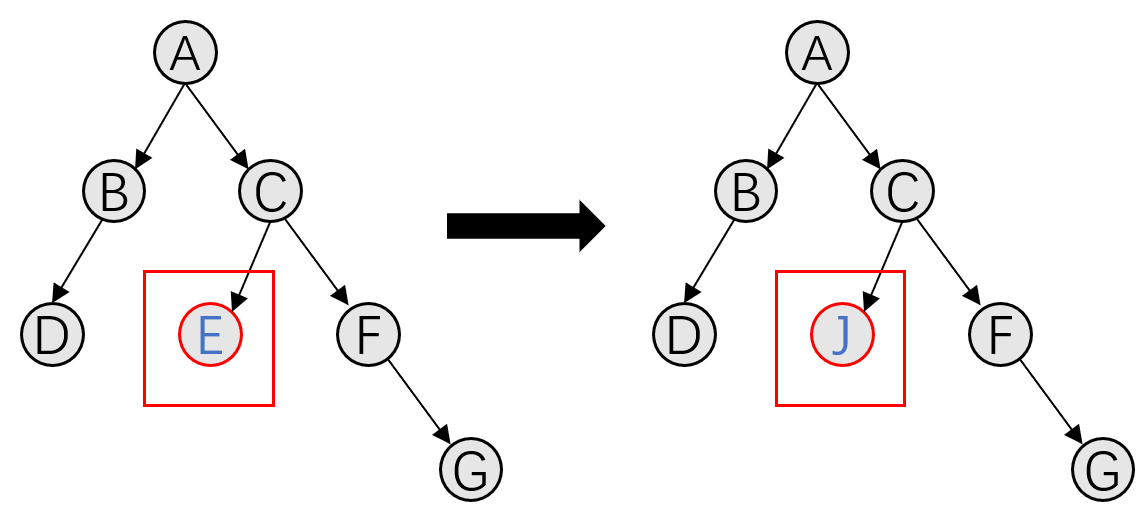
There are two types of mutation in AutoML:
Leaf Node Mutation: Randomly replaces one of the leaf nodes with other leaf nodes of the same type.
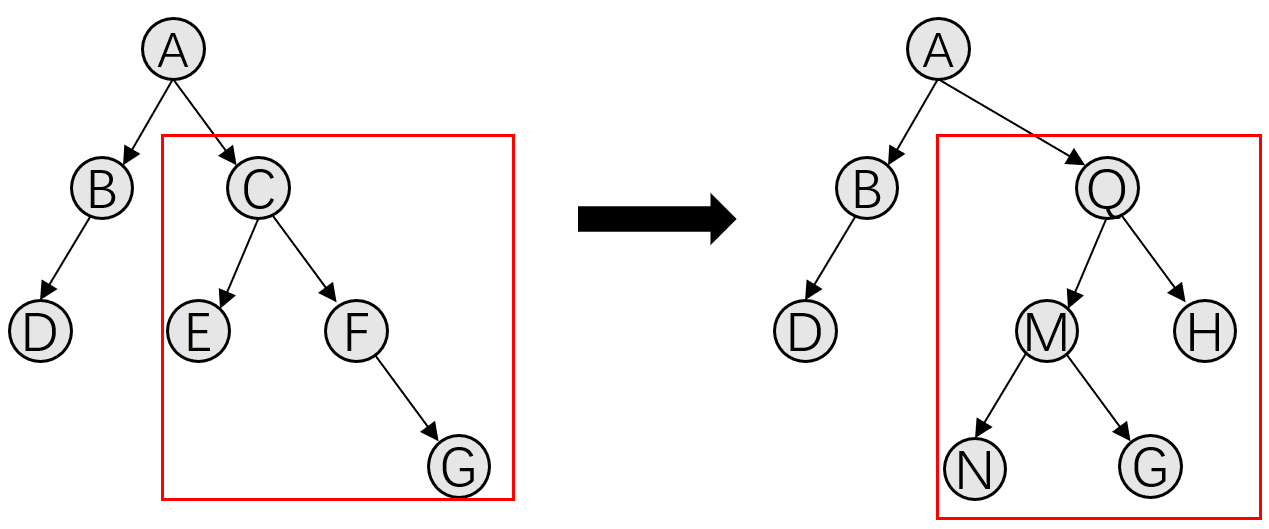
Child Node Mutation: Randomly replaces the entire subtree under the child node with a newly generated subtree that meets the validity requirements.
Evolutional Iteration Step
In each evolutional iteration, AutoML randomly selects an operation from crossover, mutation, and (random) regeneration with user
input probability to generate a new individual and evaluate its fitness score. Then the selection algorithm is used to select
population_size individuals from the population and offsprings as the next generation population.
Control Parameters
Main control parameters of GA are listed as follows:
generations: Specifies to the number of iterations in GA optimization. A larger value usually results in longer total training time, but in most cases, the iterative process will terminate when theearly_stopcondition is reached. The user can also stop the training process manually, and get the optimal solution from logging information.
population_size: Specifies the number of individuals in each generation in GA optimization. If there are too few individuals, GA has few possibilities to perform crossover and only a small part of search space is explored; on the contrary, if there are too many individuals, GA may take too much time in generating not-so-promising individuals via crossover, which could be time/resource inefficient.
offspring_size: Specifies the number of offsprings to produce in each generation. It controls of number of new individuals generated by genetic operations from population.
mutation_rate: Specifies the mutation rate for GA optimization. The value of this parameter reflects the random(global) search ability of GA, and a suitable value may prevent the algorithms from falling into a local optimum.
crossover_rate: Specifies the crossover rate for GA optimization. The value of this parameter reflects the local search ability of GA. If larger crossover rate is used, GA may converge faster, but only to local optimum.
min_layer: Specifies the minimum number of operators to form a valid pipeline.
max_layer: Specifies the maximum number of operators to form a valid pipeline.Note
The summation of
mutation_rateandcrossover_ratecannot be bigger than 1. In this case, the value of 1-mutation_rate-crossover_rateis the reproduction rate, which is the probability used in GA to (randomly)regenerate new individuals(as offsprings) in each iteration.