AutomaticClassification
- class hana_ml.algorithms.pal.auto_ml.AutomaticClassification(scorings=None, generations=None, population_size=None, offspring_size=None, elite_number=None, min_layer=None, max_layer=None, mutation_rate=None, crossover_rate=None, random_seed=None, config_dict=None, progress_indicator_id=None, fold_num=None, resampling_method=None, max_eval_time_mins=None, early_stop=None, successive_halving=None, min_budget=None, max_budget=None, min_individuals=None)
AutomaticClassification offers an intelligent search amongst machine learning pipelines for supervised classification tasks. Each machine learning pipeline contains several operators such as preprocessors, supervised classification models and transformer that follows API of hana-ml algorithms.
For AutomaticClassification parameter mappings of hana_ml and HANA PAL, please refer to the doc page: Parameter Mappings
- Parameters:
- scoringsdict, optional
AutomaticClassification supports multi-objective optimization with specified weights for each target. The goal is to maximize the target. Therefore, if you want to minimize the target, the target weight needs to be negative.
The available target options are as follows:
ACCURACY : Represents the percentage of correctly classified samples. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
AUC: Stands for Area Under Curve. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
F1_SCORE_<CLASS> : The F1 score measures the balance between precision and recall for a specific class. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
KAPPA : Cohen’s kappa coefficient measures the agreement between predicted and actual classifications. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
MCC: Matthews Correlation Coefficient measures the quality of binary classifications. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
PRECISION_<CLASS> : Precision represents the ability of a model to accurately classify instances for a specific class. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
RECALL_<CLASS> : Recall represents the ability of a model to identify instances of a specific class. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
SUPPORT_<CLASS> : The support metric represents the number of instances of a specific class. Higher values indicate better performance. It is recommended to assign a positive weight to this metric.
LAYERS: Represents the number of operators used. Lower values indicate better performance. It is recommended to assign a negative weight to this metric.
Defaults to {"ACCURACY": 1.0, "AUC": 1.0} (maximize ACCURACY and AUC).
- generationsint, optional
The number of iterations of pipeline optimization.
Defaults to 5.
- population_sizeint, optional
The number of individuals in each generation in genetic algorithm.
Defaults to 20.
- offspring_sizeint, optional
The number of offsprings to produce in each generation.
Defaults to the size of
population_size.- elite_numberint, optional
The number of elite to produce in each generation.
Defaults to 1/4 of
population_size.- min_layerint, optional
The minimum number of operators in the pipeline.
Defaults to 1.
- max_layerint, optional
The maximum number of operators in a pipeline.
Defaults to 5.
- mutation_ratefloat, optional
The mutation rate for the genetic programming algorithm.
Defaults to 0.9.
- crossover_ratefloat, optional
The crossover rate for the genetic programming algorithm.
Defaults to 0.1.
- random_seedint, optional
Specifies the seed for random number generator. Use system time if not provided.
No default value.
- config_dictstr or dict, optional
The customized configuration for the searching space. - {'light', 'default'}: use provided config_dict templates. - JSON format config_dict. It could be JSON string or dict. If it is None, the default config_dict will be used.
Defaults to None.
- progress_indicator_idstr, optional
Set the ID used to output monitoring information of the optimization progress.
No default value.
- fold_numint, optional
The number of fold in the cross validation process.
Defaults to 5.
- resampling_method{'cv', 'stratified_cv'}, optional
Specifies the resampling method for pipeline evaluation.
Defaults to 'stratified_cv'.
- max_eval_time_minsfloat, optional
Time limit to evaluate a single pipeline. The unit is minute.
Defaults to 0.0 (there is no time limit).
- early_stopint, optional
Stop optimization progress when best pipeline is not updated for the give consecutive generations. 0 means there is no early stop.
Defaults to 5.
- successive_halvingbool, optional
Specifies whether uses successive_halving in the evaluation phase.
Defaults to True.
- min_budgetint, optional
Specifies the minimum budget (the minimum evaluation dataset size) when successive halving has been applied.
Defaults to (dataset size)/5.
- max_budgetint, optional
Specifies the maximum budget (the maximum evaluation dataset size) when successive halving has been applied.
Defaults to the whole dataset size.
- min_individualsint, optional
Specifies the minimum individuals in the evaluation phase when successive halving has been applied.
Defaults to 3.
References
Under the given
config_dictandscoring, AutomaticClassification uses genetic programming to to search for the best valid pipeline. Please see Genetic Optimization in AutoML for more details.Examples
Create an AutomaticClassification instance:
>>> progress_id = "automl_{}".format(uuid.uuid1()) >>> auto_c = AutomaticClassification(generations=2, population_size=5, offspring_size=5, progress_indicator_id=progress_id) >>> auto_c.enable_workload_class("MY_WORKLOAD_CLASS")
Invoke a PipelineProgressStatusMonitor instance:
>>> progress_status_monitor = PipelineProgressStatusMonitor(connection_context=dataframe.ConnectionContext(url, port, user, pwd), automatic_obj=auto_c) >>> progress_status_monitor.start() >>> auto_c.fit(data=df_train)
Output:
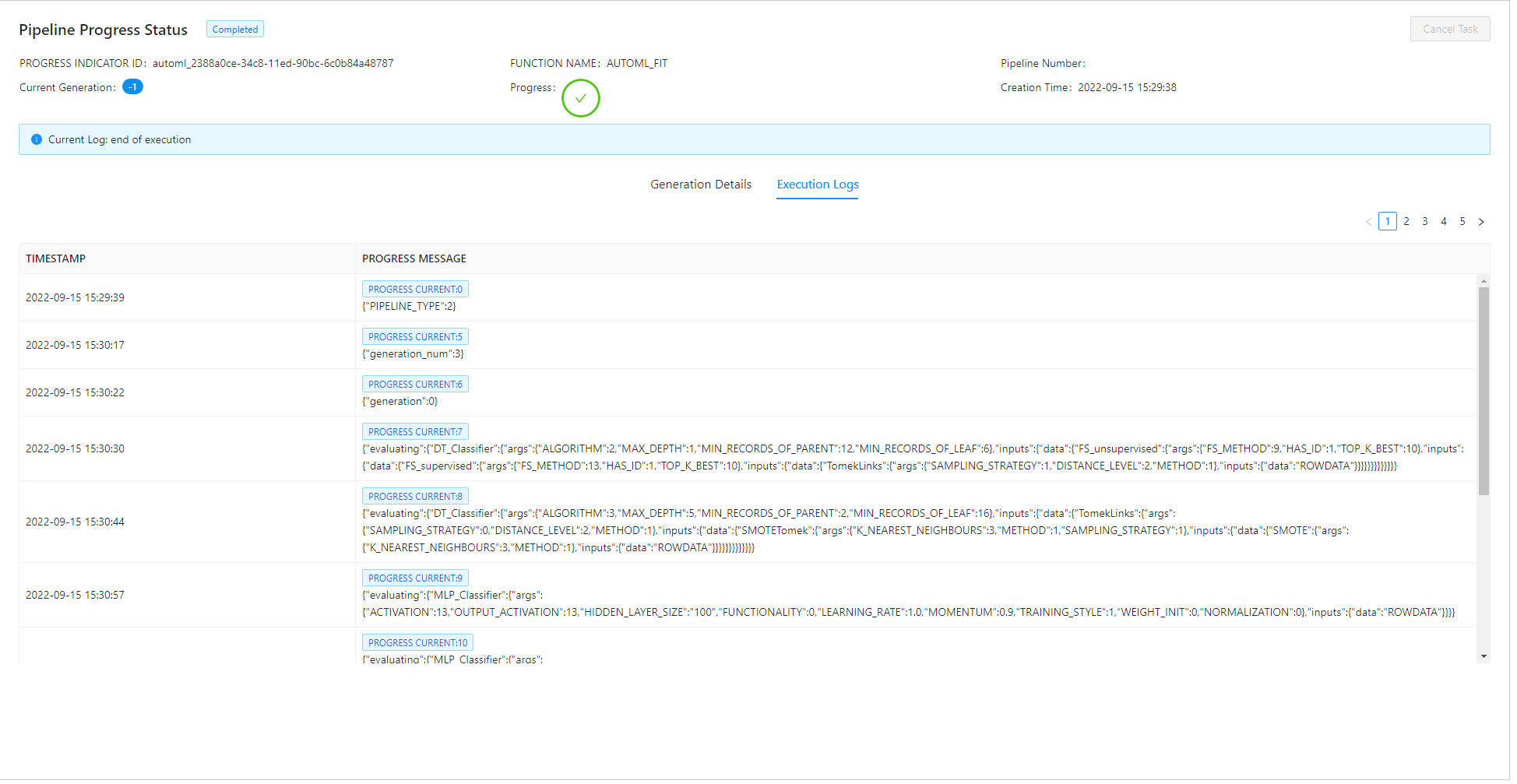
Show the best pipeline:
>>> print(auto_c.best_pipeline_.collect()) ID PIPELINE 0 {"HGBT_Classifier":{"args":{"ITER_NUM":100,"MA... SCORES {"ACCURACY":0.6726642676262828,"AUC":0.7516449...
Plot the best pipeline:
>>> BestPipelineReport(auto_c).generate_notebook_iframe()

Make prediction:
>>> res = auto_c.predict(df_test) >>> print(res.collect()) ID SCORES 702 1 502 0 ... ... 103 0 208 0 140 0 282 1 581 0
If you want to use an existing pipeline to fit and predict:
>>> pipeline = auto_c.best_pipeline_.collect().iat[0, 1] >>> auto_c.fit(df_train, pipeline=pipeline) >>> res = auto_c.predict(df_test)
- Attributes:
- best_pipeline_: DataFrame
Best pipelines selected, structured as follows:
1st column: ID, type INTEGER, pipeline IDs.
2nd column: PIPELINE, type NVARCHAR, pipeline contents.
3rd column: SCORES, type NVARCHAR, scoring metrics for pipeline.
Available only when the
pipelineparameter is not specified during the fitting process.- model_DataFrame or list of DataFrames
If pipeline is not None, structured as follows
1st column: ROW_INDEX.
2nd column: MODEL_CONTENT.
If auto-ml is enabled, structured as follows
1st DataFrame:
1st column: ROW_INDEX.
2nd column: MODEL_CONTENT.
2nd DataFrame: best_pipeline_
- info_DataFrame
Related info/statistics for AutomaticClassification pipeline fitting, structured as follows:
1st column: STAT_NAME.
2nd column: STAT_VALUE.
Methods
cleanup_progress_log(connection_context)Cleanup the progress log.
delete_config_dict([operator_name, ...])Delete the content of the config dict.
Disables the mlflow autologging.
Disables the workload class check.
display_config_dict([operator_name, category])Display the config dict.
display_progress_table(connection_context)Return the progress table.
enable_mlflow_autologging([schema, meta, ...])Enables the mlflow autologging.
evaluate(data[, pipeline, key, features, ...])This function is to evaluate a pipeline.
fit(data[, key, features, label, pipeline, ...])Fit function of AutomaticClassification/AutomaticRegression/AutomaticTimeSeries.
Return the best pipeline.
get_workload_classes(connection_context)Returns the available workload classes information.
make_future_dataframe([data, key, periods])Create a new dataframe for time series prediction.
Persist the progress log.
pipeline_plot([name, iframe_height])Pipeline plot.
predict(data[, key, features, model, ...])Predict function for AutomaticClassification/AutomaticRegression/AutomaticTimeSeries.
reset_config_dict([connection_context, ...])Reset config dict.
score(data[, key, features, label, model, ...])Pipeline model score function, with final estimator being a classifier.
update_category_map(connection_context)Update the list of operators.
update_config_dict(operator_name[, ...])Update the config dict.
- reset_config_dict(connection_context=None, template_type='default')
Reset config dict.
- Parameters:
- connection_contextConnectionContext, optional
If it is set, the default config dict will use the one stored in SAP HANA DB.
Defaults to None.
- template_type{'default', 'light'}, optional
HANA config dict type.
Defaults to 'default'.
- score(data, key=None, features=None, label=None, model=None, random_state=None, top_k_attributions=None, verbose_output=None)
Pipeline model score function, with final estimator being a classifier.
- Parameters:
- dataDataFrame
Data for pipeline model scoring.
- keystr, optional
Name of the ID column.
Mandatory if
datais not indexed, or the index ofdatacontains multiple columns.Defaults to the single index column of
dataif not provided.- featureslist of str, optional
Names of the feature columns. Should be same as those provided in the training data.
If
featuresis not provided, it defaults to all non-ID, non-label columns.- labelstr, optional
Name of the dependent variable.
Defaults to the name of the last non-ID column.
- modelDataFrame, optional
DataFrame that contains the pipeline model for scoring.
Defaults to the fitted model of the current class instance.
- random_stateDataFrame, optional
Specifies the random seed.
Defaults to -1(system time).
- top_k_attributionsint, optional
Display the top k attributions in reason code.
Defaults to PAL's default value.
- verbose_outputbool, optional
True: Outputs the probability of all label categories.
False: Outputs the category of the highest probability only.
Defaults to True.
- cleanup_progress_log(connection_context)
Cleanup the progress log.
- Parameters:
- connection_contextConnectionContext
The connection object to a SAP HANA database.
- delete_config_dict(operator_name=None, category=None, param_name=None)
Delete the content of the config dict.
- Parameters:
- operator_namestr, optional
Deletes the operator based on the given name in the config dict.
Defaults to None.
- categorystr, optional
Deletes the whole given category in the config dict.
Defaults to None.
- param_namestr, optional
Deletes the parameter based on the given name once the operator name is provided.
Defaults to None.
- disable_mlflow_autologging()
Disables the mlflow autologging.
- disable_workload_class_check()
Disables the workload class check. Please note that the AutomaticClassification/AutomaticRegression/AutomaticTimeSeries may cause large resource. Without setting workload class, there's no resource restriction on the training process.
- display_config_dict(operator_name=None, category=None)
Display the config dict.
- Parameters:
- operator_namestr, optional
Only displays the information on the given operator name.
Defaults to None.
- categorystr, optional
Only displays the information on the given category.
Defaults to None.
- display_progress_table(connection_context)
Return the progress table.
- Parameters:
- connection_contextConnectionContext
The connection object to a SAP HANA database.
- Returns:
- DataFrame
Progress table.
- enable_mlflow_autologging(schema=None, meta=None, is_exported=False, registered_model_name=None)
Enables the mlflow autologging.
- Parameters:
- schemastr, optional
Defines the model storage schema for mlflow autologging.
Defaults to the current schema.
- metastr, optional
Defines the model storage meta table for mlflow autologging.
Defaults to 'HANAML_MLFLOW_MODEL_STORAGE'.
- is_exportedbool, optional
Determines whether export a HANA model to mlflow.
Defaults to False.
- registered_model_namestr, optional
MLFlow registered_model_name.
Defaults to None.
- evaluate(data, pipeline=None, key=None, features=None, label=None, categorical_variable=None, resampling_method=None, fold_num=None, random_state=None)
This function is to evaluate a pipeline.
- Parameters:
- dataDataFrame
Data for pipeline evaluation.
- pipelinejson str or dict
Pipeline to be evaluated.
- keystr, optional
Name of the ID column.
Mandatory if
datais not indexed, or the index ofdatacontains multiple columns.Defaults to the single index column of
dataif not provided.- featureslist of str, optional
Names of the feature columns. If
featuresis not provided, it defaults to all non-ID, non-label columns.- labelstr, optional
Name of the dependent variable.
Defaults to the name of the last non-ID column.
- categorical_variablestr or list of str, optional
Specify INTEGER column(s) that should be be treated as categorical data. Other INTEGER columns will be treated as continuous.
Defaults to None.
- resampling_methodcharacter, optional
The resampling method for pipeline model evaluation. For different pipeline, the options are different.
regressor: {'cv', 'stratified_cv'}
classifier: {'cv'}
timeseries: {'rocv', 'block'}
Defaults to 'stratified_cv' if the estimator in
pipelineis a classifier, and defaults to(and can only be) 'cv' if the estimator inpipelineis a regressor, and defaults to 'rocv' if if the estimator inpipelineis a timeseries.- fold_numint, optional
The fold number for cross validation.
Defaults to 5.
- random_stateint, optional
Specifies the seed for random number generator.
0: Uses the current time (in seconds) as the seed.
Others: Uses the specified value as the seed.
- Returns:
- DataFrame
DataFrame of scores:
Score Name.
Score Value.
- fit(data, key=None, features=None, label=None, pipeline=None, categorical_variable=None, background_size=None, background_sampling_seed=None, model_table_name=None)
Fit function of AutomaticClassification/AutomaticRegression/AutomaticTimeSeries.
- Parameters:
- dataDataFrame
The training data.
- keystr, optional
Name of the ID column.
If
keyis not provided, then:if
datais indexed by a single column, thenkeydefaults to that index column;otherwise, it is assumed that
datacontains no ID column.
- featureslist of str, optional
Names of the feature columns.
If
featuresis not provided, it defaults to all non-ID, non-label columns.- labelstr, optional
Name of the dependent variable.
Defaults to the name of the last non-ID column.
- pipelinestr or dict, optional
Directly uses the input pipeline to fit.
- categorical_variablestr or list of str, optional
Specify INTEGER column(s) that should be be treated as categorical data. Other INTEGER columns will be treated as continuous.
- background_sizeint, optional
If set, the reason code procedure will be enabled. Only valid when pipeline is provided.
Defaults to None.
- background_sampling_seedint, optional
Specifies the seed for random number generator in the background sampling. Only valid when pipeline is provided. - 0: Uses the current time (in second) as seed - Others: Uses the specified value as seed
Defaults to 0.
- model_table_namestr, optional
Specifies the HANA model table name instead of the generated temporary table.
Defaults to None.
- Returns:
- A fitted object.
- property fit_hdbprocedure
Returns the generated hdbprocedure for fit.
- get_best_pipeline()
Return the best pipeline.
- get_workload_classes(connection_context)
Returns the available workload classes information.
- Parameters:
- connection_contextstr, optional
The connection to SAP HANA.
- make_future_dataframe(data=None, key=None, periods=1)
Create a new dataframe for time series prediction.
- Parameters:
- dataDataFrame, optional
The training data contains the index.
Defaults to the data used in the fit().
- keystr, optional
The index defined in the training data.
Defaults to the specified key in fit function or the data.index or the first column of the data.
- periodsint, optional
The number of rows created in the predict dataframe.
Defaults to 1.
- Returns:
- DataFrame
- persist_progress_log()
Persist the progress log.
- pipeline_plot(name='my_pipeline', iframe_height=450)
Pipeline plot.
- Parameters:
- namestr, optional
The name of the pipeline plot.
Defaults to 'my_pipeline'.
- iframe_heightint, optional
The display height.
Defaults to 450.
- predict(data, key=None, features=None, model=None, show_explainer=False, top_k_attributions=None)
Predict function for AutomaticClassification/AutomaticRegression/AutomaticTimeSeries.
- Parameters:
- dataDataFrame
Data to be predicted.
- keystr, optional
Name of the ID column.
Mandatory if
datais not indexed, or is indexed by multiple columns.Defaults to the index of
dataifdatais indexed by a single column.- featureslist of str, optional
Names of the feature columns.
If
featuresis not provided, it defaults to all non-ID columns.- modelDataFrame, optional
The model to be used for prediction.
Defaults to the fitted model (model_).
- show_explainerbool, optional
If True, the reason code will be returned. Only valid when background_size is provided during the fit process.
Defaults to False
- top_k_attributionsint, optional
Display the top k attributions in reason code.
Defaults to PAL's default value.
- Returns:
- DataFrame
Predicted result, structured as follows:
1st column: Data type and name same as the 1st column of
data.2nd column: SCORE, predicted values(for regression) or class labels(for classification).
- property predict_hdbprocedure
Returns the generated hdbprocedure for predict.
- update_category_map(connection_context)
Update the list of operators.
- Parameters:
- connection_contextstr, optional
The connection to SAP HANA.
- update_config_dict(operator_name, param_name=None, param_config=None)
Update the config dict.
- Parameters:
- operator_namestr
The name of operator.
- param_namestr, optional
The parameter name to be updated. If the parameter name doesn't exist in the config dict, it will create a new one.
Defaults to None.
- param_configany, optional
The parameter config value.
Defaults to None.
Inherited Methods from PALBase
Besides those methods mentioned above, the AutomaticClassification class also inherits methods from PALBase class, please refer to PAL Base for more details.