
 Standardfunktionen
Standardfunktionen

Allgemeines
Werte von Elementen beziehungsweise Attributen der XML-Message (also der Payload) sind technisch gesehen eine Zeichenkette (ein String). Daher erwarten alle Standardfunktionen, die auf Feldwerten operieren, Argumente vom Typ String und geben einen Wert vom Typ String zurück. Trotzdem kann natürlich semantisch der übergebene Wert einen anderen Datentyp haben, nämlich den, den Sie bei der Definition des Schemas zur Payload für das Feld angegeben haben. Für Standardfunktionen gibt es folgendes Standardverhalten:
● Je nach Standardfunktion werden die übergebenen Werte mit Hilfe einer Datentypkonvertierung (über einen cast) in für die Funktion sinnvolle Werte überführt. Wenn der Wert nicht sinnvoll interpretiert werden kann, löst die Mapping-Laufzeit eine Java-Exception aus.
● If-Klauseln werten Bedingungen aus, die boolesche Werte liefern. Standardfunktionen, die boolesche Werte zurückgeben, geben entweder den String true oder false zurück. Standardfunktionen, die boolesche Werte erwarten, interpretieren die Werte „1“ und „true“ (Groß-/Kleinschreibung spielt hier keine Rolle) als true und alle anderen Werte als false.

Siehe auch: Laufzeitverhalten.
Funktionsübersicht
Die Datenfluss-Objekte zu Standardfunktionen haben den folgenden Aufbau:
● Die meisten Datenfluss-Objekte haben auf der linken Seite zwei oder drei Eingänge und einen Ausgang, der immer auf der rechten Seite liegt.
● Die If-Funktionen haben eine Rauten- beziehungsweise Dreiecksform.
● Außerdem gibt es noch Konvertierungsfunktionen mit einem Eingang/Ausgang und Funktionen, die ohne Eingaben einen Wert liefern.
●
Standardfunktionen, für die zusätzliche Angaben benötigt
werden, sind mit einem Sternchen ( ) gekennzeichnet. Um den Dialog für die Funktionseigenschaften aufzurufen,
doppelklicken Sie auf das Datenfluss-Objekt.
) gekennzeichnet. Um den Dialog für die Funktionseigenschaften aufzurufen,
doppelklicken Sie auf das Datenfluss-Objekt.
Die folgende Grafik gibt einen Überblick über alle möglichen Formen für Datenfluss-Objekte:
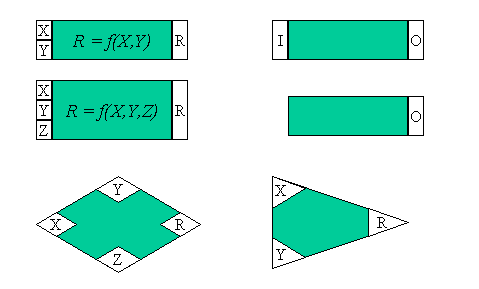
Um die Verwendung der einzelnen Funktionen zu erläutern, sind die Eingabe-Kästchen in der Grafik mit X, Y, Z beziehungsweise I bezeichnet, der Ergebniswert mit R beziehungsweise O. In den folgenden Tabellen werden alle Standardfunktionen an Hand dieser Ein-/Ausgabevariablen beschrieben. Im Datenfluss-Editor liefern andere Datenfluss-Objekte, die mit den Funktionen über die jeweiligen Verbindungs-Kästchen verbunden sind, die Eingabewerte beziehungsweise bekommen das Ergebnis der Operation. Sie können die Funktionen auch beliebig miteinander kombinieren (vorausgesetzt, die an eine Funktion übergebenen Werte können interpretiert werden).
Arithmetik
Für diese Kategorie sind nur numerische Eingabewerte zugelassen (auch solche mit Nachkommastellen). Wenn der Wert nicht als Zahl interpretiert werden kann, wird eine Java-Exception ausgelöst. Ansonsten werden alle Berechnungen mit der Präzision des Java-Datentyps float durchgeführt. Das Format des Ergebniswerts hängt vom Ergebnis ab:
● Ist das Ergebnis ein Wert mit Nachkommastellen, bleiben diese erhalten
● Ausnahme: 0er-Nachkommastellen werden abgeschnitten, das heißt, das Ergebnis der Berechnung 4.2 – 0.2 ist 4 und nicht 4.0.
Funktionsname |
Funktion |
add |
R = X + Y |
subtract |
R = X - Y |
equalsA |
R = true, falls der Wert X gleich dem Wert Y ist, false sonst. Die Werte werden numerisch interpretiert, der Wert 1.5 ist also gleich 1.50. |
abs |
O = absoluter Wert von I |
sqrt |
R ist die Quadratwurzel von X |
sqr |
R ist die Quadratzahl von X |
sign |
R = 1, wenn X eine positive Zahl ist R = 0, wenn X gleich 0 ist R = -1, wenn X eine negative Zahl ist. |
neg |
R = -X |
1/x |
R ist der Kehrwert von X |
power |
R = XY |
less |
True, wenn X < Y, false sonst |
greater |
True, wenn X > Y, false sonst |
multiply |
R = X * Y |
divide |
R = X / Y |
max |
R = Maximum der beiden Werte X und Y |
min |
R = Minimum der beiden Werte X und Y |
ceil |
O = Kleinstmöglicher Integer-Wert (bis minus 'unendlich'), der nicht kleiner ist als das Argument I. Entspricht der Java-Funktion java.lang.Math.ceil(). |
floor |
O = Größtmöglicher Integer-Wert, der nicht größer ist als das Argument I. Entspricht der Java-Funktion java.lang.Math.floor(). |
round |
O = Integer-Wert zurück, der am nächsten am Wert des Arguments I ist. Entspricht der Java-Funktion java.lang.Math.round(). |
counter |
O = Anzahl der Aufrufe dieses Zielfeld-Mappings, wobei Sie den Initialwert und das Inkrement des Zählers bei den Funktionseigenschaften angeben. |
FormatNum |
Konvertiert I nach Anwendung einer Musters, das Sie über die Funktionseigenschaften festlegen. Die möglichen Muster sind die gleichen wie in der Java-Klasse java.text.DecimalFormat. |
Boolesch
Alle Funktionen dieser Kategorie erwarten boolesche Eingabewerte (siehe oben).
Funktionsname |
Funktion |
And |
R ist true, wenn X und Y den Wert true haben, ansonsten ist R false. |
Or |
R ist true, wenn X oder Y den Wert true haben, ansonsten ist R false. |
Not |
● O ist false, wenn I den Wert true hat ● O ist true, wenn I den Wert false hat |
Equals |
Vergleicht die beiden booleschen Werte X und Y und gibt true zurück, wenn beide gleich sind, ansonsten false. Nicht boolesche Werte werden als false interpretiert (siehe oben). Für den Vergleich von Strings verwenden Sie die Funktionen equalsS beziehungsweise compare der Kategorie Text. |
notEquals |
R = Not(Equals(X,Y)) |
if |
● Wenn Bedingung X erfüllt ist (true liefert): R = Y ● Wenn Bedingung X nicht erfüllt ist (false liefert): R = Z |
Wenn Bedingung X erfüllt ist (true liefert): R = Y. Ansonsten wird das Zielfeld nicht erzeugt. |
Konstanten
Da diese Funktionen keine Eingabewerte haben, gehören Sie zu den erzeugenden Funktionen.
Funktion |
Verwendung |
Constant |
O liefert eine beliebige String-Konstante, die Sie im Dialog für die Funktionseigenschaften eingeben. |
Kopiert für ein mehrfach auftretendes Element den Wert an einer festgelegten Position der Ausgangsstruktur auf das zugeordnete Zielfeld. |
|
sender |
O liefert den Namen des Sender-Business-Systems. Bei einem Test des Message-Mappings im Integration Builder wird Test_Sender_System ausgegeben. |
receiver |
O liefert den Namen des Emfpänger-Business-Systems. Bei einem Test des Message-Mappings im Integration Builder wird Test_Receiver_System ausgegeben. |
Konvertierungen
Funktion |
Verwendung |
FixValues |
Ausführung eines Werte-Mappings über eine feste Wertetabelle, die Sie über die Funktionseigenschaften füllen. Die Tabelle wird zusammen mit dem aktuellen Message-Mapping gespeichert und ist nur einmal verwendbar. |
Datum
Bei den folgenden Funktionen können Sie das Datumsformat für das Ausgangs- beziehungsweise Zielformat über den Dialog für die Funktionseigenschaften festlegen.
Das Format entspricht der Konvention wie sie in der Standard-Java-Klasse java.util.SimpleDateFormat festgelegt ist. Der Funktionseigenschaften-Dialog bietet auch einen Wizard, über den Sie die gängigsten Datumsformate eingeben können.
Funktion |
Verwendung |
currentDate |
Gibt das aktuelle Datum über O zurück. Diese Funktion gehört zu den erzeugenden Funktionen. |
DateTrans |
Konvertiert ein Datumsformat I in ein anderes Datums-Format O. |
DateBefore |
R = true, wenn das Datum X vor dem Datum Y liegt, false sonst |
DateAfter |
R = true, wenn das Datum X nach dem Datum Y liegt, false sonst |
CompareDates |
R = 1, wenn das Datum
X nach dem Datum Y liegt |
Knotenfunktionen
Funktion |
Verwendung |
Wenn in Ihrer Zielstruktur Elemente zur Struktuierung vorhanden sind, die es in der Ausgangsstruktur nicht gibt, können Sie solche Elemente mit dieser Funktion einfügen. Mit der Bedingung I können Sie steuern, ob das Element eingefügt wird oder nicht. Das Element in der Zielstruktur verbinden Sie mit O. |
|
Verwerfen aller übergeordneten Kontexte eines Ausgangsfeldes. Auf diese Weise können alle Hierarchiestufen löschen und eine Liste erzeugen. |
|
replaceValue |
Ersetzt den Wert I durch einen Wert, den Sie im Dialog für die Funktionseigenschaften festlegen können. |
O = true, falls das dem Eingang I zugeordnete Ausgangsfeld in der XML-Instanz existiert. Ansonsten false. |
|
Fügt einen Kontextwechsel für ein Element ein. |
|
Ersetzt alle Werte innerhalb aller Kontexte durch einen leeren String. Ist eine nützliche Funktion in Kombination mit SplitByValue. |
|
Repliziert einen Wert eines einfach auftretenden Feldes, um ihn mit den Werten eines mehrfach auftretenden Wertes paarweise als Rekord kombinieren zu können. |
|
sort |
Sortiert alle Werte des mehrfach auftretenden Eingangsfeldes I innerhalb des bestehenden oder gesetzten Kontextes. Die Sortierung ist stabil (gleiche Elemente werden beim Sortieren nicht in ihrer Reihenfolge vertauscht) und sortiert die Werte in O(n*log(n)) Schritten. In den Funktionseigenschaften können Sie festlegen, ob die Werte numerisch oder lexikographisch (mit oder ohne Berücksichtigung von Groß-/Kleinschreibung) sortiert werden sollen, und ob aufsteigend oder absteigend. |
sortByKey |
Wie sort, nur mit zwei Eingangsparametern für die Sortierung von (Schlüssel, Wert)-Paaren. Sie können sich diese Sortierung wie die von einer Tabelle mit zwei Spalten vorstellen: ● Mit dem ersten Parameter übergeben Sie Schlüsselwerte der ersten Spalte, nach denen die Tabelle sortiert werden soll. Falls Sie die Schlüsselwerte in den Funktionseigenschaften als numerisch klassifiziert haben, darf kein Schlüsselwert der Konstante ResultList.SUPPRESS entsprechen. Siehe auch: Das ResultList-Objekt. ● Mit dem zweiten Parameter übergeben Sie die Werte der zweiten Tabellenspalte. Wenn es mehr oder weniger Schlüssel als Werte gibt, löst die Mapping-Laufzeit eine Ausnahme aus. Die Funktion gibt als Ergebnis eine Queue mit den nach den Schlüsseln sortierten Werten zurück. |
mapWithDefault |
Ersetzt leere Kontexte der Eingangsqueue durch einen Default-Wert, den Sie in den Funktionseigenschaften angeben.
Beispiel: Wenn „Default“ der Default-Wert ist und A|B1,B2| |C| |D die Eingangsqueue, liefert mapWithDefault die folgende Ausgangsqueue: A | B1,B2 | Default | C | Default |D. Die Funktion entspricht folgender Kombination von Standardfunktionen: If( []field, exists([]field), Constant([value=default])) |
Diese Funktion hat zwei Eingangsqueues, bei denen die Anzahl der Werte gleich sein muss. Um die Ergebnisqueue zu erzeugen, übernimmt die Funktion die Werte der ersten Queue und kombiniert sie mit den Kontextwechseln der zweiten Queue. |
Statistik
Die Funktionen dieser Funktionskategorie sind gedacht für Ausgangsfelder, die mehrfach in der Ausgangsstruktur vorkommen (maxOccurs = i > 1).
Funktion |
Verwendung |
sum |
R = Summe der Werte X1 bis Xi eines Kontexts |
average |
R = Durchschnitt der Werte X1 bis Xi eines Kontexts |
count |
R = Anzahl der Felder in einem Kontext (i) |
index |
R = Index i von Xi. Sie legen in den Funktionseigenschaften folgendes fest: Den Initialwert von i, das Inkrement und ob der Indexwert zu Beginn eines neuen Kontextes neu initialisiert werden soll oder nur ein Mal für die gesamte Ausgangsstruktur. |
Text
Bei Positionsangaben entspricht die 0.Position dem ersten Zeichen im String.
Funktion |
Verwendung |
substring |
Gibt für einen String I einen Teilstring O zurück. Um die Position des Teilstrings anzugeben, verwenden Sie den Dialog für die Funktionseigenschaften. Beispiel: substring(„Hello“, 0,1) = „H“, das heißt, es wird der Teilstring vom Startindex 0 bis zum Endindex 1 (exklusive Position 1) gebildet. |
concat |
R = Verkettung der Strings X und Y (ohne Trennzeichen). Beispiel: X = „Mrs.“; Y = „Miller“; R = „Mrs.Miller“. Verwenden Sie den Dialog für die Funktionseigenschaften, um ein Trennzeichen innerhalb der Verkettung einzufügen. |
equalsS |
R = true, falls der String X gleich dem String Y ist, false sonst. |
indexOf |
R = Erste Position, an der der String Y in X gefunden wird und –1 falls er nicht darin vorkommt. |
indexOf |
R = Erste Position ab der Position Z, an der der String Y in X gefunden wird und –1 falls er nicht darin vorkommt. |
lastIndexOf |
R = Letzte Position, an der der String Y in X gefunden wird und –1 falls er nicht darin vorkommt. |
lastIndexOf |
R = Letzte Position ab der Position Z, an der der String Y in X gefunden wird und –1 falls er nicht darin vorkommt. |
compare |
Vergleicht String X mit String Y: R = 0, wenn die
Strings gleich sind i gibt lexikographisch die Differenz zwischen beiden Strings an. Die Funktion verhält sich genauso wie die Methode compareTo() der JDK-Klasse java.lang.String. |
replaceString |
X: String, in dem etwas ersetzt werden soll Y: Zeichenfolge, die in X zu ersetzen ist Z: Zeichenfolge, die Y ersetzen soll R = Zeichenfolge, in der jedes Auftreten von Y in X durch Z ersetzt ist.
X = "sparring with a purple porpoise" Y = “p” Z = “t” R = "starring with a turtle tortoise"
|
length |
O = Länge des Strings |
endsWith |
R = true, wenn Y die letzte Zeichenfolge in X ist;false sonst. |
startsWith |
R = true, wenn Y die erste Zeichenfolge in X ist;false sonst. |
startWith |
R = true, wenn Y in X ab Position Z übereinstimmt;false sonst. |
toUpperCase |
Konvertiert alle Kleinbuchstaben von I zu Großbuchstaben |
trim |
Entfernt alle Whitespace Zeichen (Leerzeichen, Tabs, Return) am Anfang und am Ende eines Strings. Verhält sich genauso wie die Methode trim() der JDK-Klasse java.lang.String. |
toLowerCase |
Konvertiert alle Großbuchstaben von I zu Kleinbuchstaben |
