
 Scenario for Using Write-Optimized DataStore
Objects
Scenario for Using Write-Optimized DataStore
Objects

A plausible scenario for write-optimized DataStore objects is exclusive saving of new, unique data records, for example in the posting process for documents in retail. In the example below, however, write-optimized DataStore objects are used as the EDW layer for saving data.
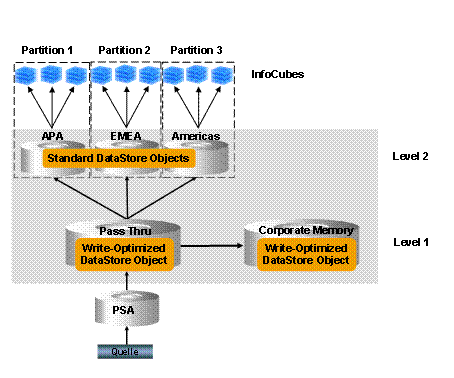
There are three main steps to the entire data process:
...
1. Loading the data into the BI system and storing it in the PSA
At first, the data requested by the BI system is stored in the PSA. A PSA is created for each DataSource and each source system. The PSA is the storage location for incoming data in the BI system. Requested data is saved, unchanged, to the source system.
2. Processing and storing the data in DataSource objects
In the second step, the data is posted at the document level to a write-optimized DataStore object (“pass through”). The data is posted from here to another write-optimized DataStore object, known as the corporate memory. The data is then distributed from the “pass through“ to three standard DataStore objects, one for each region in this example. The data records are deleted after posting.
3. Storing data in InfoCubes
In the final step, the data is aggregated from the DataStore objects to various InfoCubes depending on the purpose of the query, for example for different distribution channels. Modeling the various partitions individually means that they can be transformed, loaded and deleted flexibly.