
 Datenbank-Tabellenpuffer
Datenbank-Tabellenpuffer

Verwendung
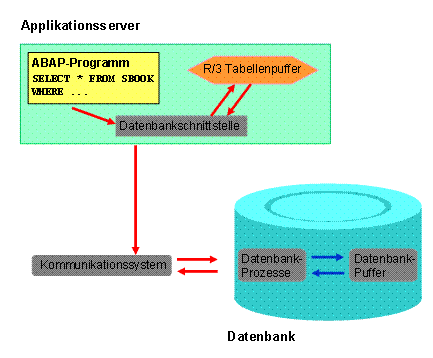
Die Pufferung einer Tabelle erhöht die Performance beim Zugriff auf die in der Tabelle enthaltenen Datensätze. Die Tabellenpuffer befinden sich lokal auf jedem Applikationsserver des Systems. Aus dem Puffer des Applikationsservers kann direkt auf die Daten gepufferter Tabellen zugegriffen werden. Zeitaufwendige Zugriffe auf die Datenbank werden dadurch eingespart. Die folgenden Abbildung zeigt, wie ein Tabellenpuffer mit der Datenbank kommuniziert.
Funktionsumfang
Die Pufferung ist insbesondere in Client/Server-Umgebungen wichtig, da hier die Zugriffszeit über das Netz wesentlich höher liegt als die Zugriffszeit auf eine lokal gepufferte Tabelle. Je nach Netzwerkbelastung beträgt dieser Faktor 10-100.
Diese Performancedifferenz ist in zentralen Systemen (Systemen mit nur einem Applikationsserver) etwas geringer als in lokalen Systemen (Systemen mit mehreren Applikationsservern). Jedoch wirkt sich auch in zentralen Systemen die Einsparung von Prozesswechseln und die gegenüber dem Datenbanksystem gezieltere Pufferung merklich auf die Performance aus.
Puffer füllen
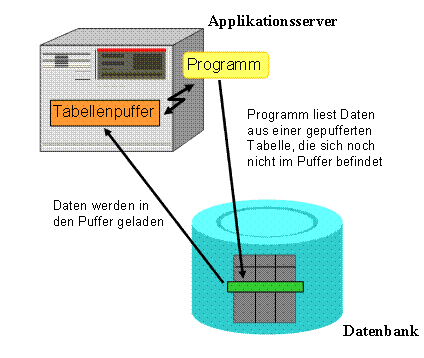
Greift ein Programm auf Daten einer gepufferten Tabelle zu, so wird über die Datenbank-Schnittstelle ermittelt, ob sich diese Daten im Puffer des Applikationsservers befinden. Ist dies der Fall, so werden die Daten direkt aus dem Puffer gelesen. Sind die Daten nicht im Puffer des Applikationsservers enthalten, so werden die Daten von der Datenbank gelesen und dabei in den Puffer geladen. Der nächste Zugriff auf diese Daten kann damit aus dem Puffer stattfinden.
Welche Sätze beim Zugriff in den Puffer geladen werden, ist durch die Pufferungsart bestimmt. Dies wird in der folgenden Abbildung erläutert:
Synchronisation der lokalen Puffer
Eine gepufferte Tabelle wird in der Regel auf allen Applikationsservern gelesen und dort im Puffer gehalten. Ändert ein Programm auf einem der Applikationsserver die in der Tabelle enthaltenen Daten, so wird dies durch die Datenbank-Schnittstelle in einer Protokolltabelle vermerkt. Auf allen anderen Applikationsservern haben die Puffer noch den alten Stand und die Programme lesen damit unter Umständen veraltete Daten.
In einem festen Zeitintervall, beispielsweise alle 1-2 Minuten, läuft ein Synchronisationsmechanismus. Das System liest die Protokolltabelle und invalidiert die Pufferinhalte, die von anderen Servern geändert wurden. Beim nächsten Zugriff werden die Daten invalidierter Tabellen dann direkt von der Datenbank gelesen und im Puffer aktualisiert. Weitere Informationen finden Sie unter Synchronisation der lokalen Puffer.
Verdrängung
Wenn durch Einlagern neuer Daten Platzbedarf im Puffer entsteht, werden diejenigen Daten verdrängt, auf die am längsten nicht zugegriffen wurde. Die Verdrängung findet asynchron zu bestimmten Zeitpunkten statt, die dynamisch anhand der Zugriffe auf den Puffer bestimmt werden.

Verdrängung findet nur statt, wenn zu diesem Zeitpunkt der freie Platz im Puffer einen voreingestellten Wert unterschreitet oder die Zugriffsqualität zu schlecht ist.
Tabellenpuffer zurücksetzen
Über die Eingabe von $TAB im Befehlsfeld können die Tabellenpuffer auf dem entsprechenden Applikationsserver zurückgesetzt werden. Das System invalidiert alle Daten im Puffer.

Verwenden Sie diesen Befehl nur, wenn Inkonsistenzen im Puffer entstanden sind! Das Füllen der Puffer kann in großen Systemen mehrere Stunden dauern. Während dieser Zeit ist die Performance erheblich beeinträchtigt.
Siehe auch:
Einschränkungen und Empfehlungen für die Pufferung von Tabellen
Technische Realisierung von Tabellenpuffern
Zugriffe, die direkt auf die Datenbank gehen