
 Architecture
Architecture

Overview
The architecture of the Java Scheduler is based on two failover-enabled services that control the aspects of job scheduling and execution. Jobs are implemented on the basis of message-driven beans and run in the EJB container. The figure below outlines the architecture of the Java Scheduler.
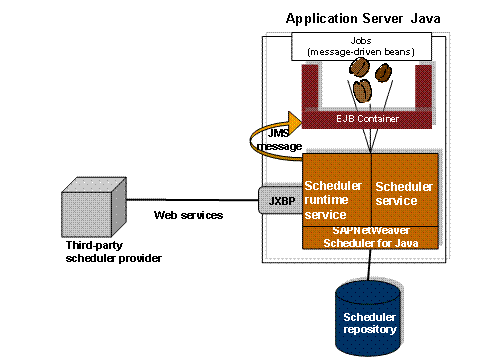
Services
The Java Scheduler defines two services:
● Scheduler Runtime Service
Controls all aspects of the runtime of a job. It handles the execution of jobs on the node where it is running, and provides error handling, maintains job definitions and job runtime information, such as job parameters and log files.
● Scheduler Service
Schedules jobs deployed on the application server and submits them to the scheduler runtime service. The scheduler service accepts requests for rescheduling, canceling and deleting jobs.
The two services persist the complete state of the Java Scheduler in the database.
Service Failover
In cluster environment, the scheduler runtime service is deployed and runs on every cluster node. The scheduler service is also deployed on all cluster nodes but it runs only on a single node at a time. The node where it runs is designated as the singleton node. If the singleton node goes down, the scheduler service gets activated on another cluster node. This mechanism ensures the scheduler service failover.
If a job is running on a node and that node goes down, the execution of the job is resumed on another node. There is no data loss because the complete state of the Java Scheduler is persisted.
Jobs
Jobs are implemented on the basis of message-driven beans. A message-driven bean containing a job is called a JobBean. The execution of JobBeans is handled by the EJB container. A JobBean is executed when it receives a Java Messaging Service (JMS) message from the scheduler runtime service. In cluster environment, the JMS is responsible for load balancing: it decides which JobBean instance on which node gets the request to run.
From a purely scheduling perspective, a job is executed when certain time-based start conditions, such as a particular time of the day, are fulfilled. The start conditions of a job are defined when you schedule the job.
For more information about the basic concepts of job definition, scheduler task, and job, see Scheduler Job Definition, Job, and Task
External API
Java eXternal Interface for Background Processing (JXBP) is a public API exposed as a Web service. It provides third-party scheduler providers with access to the Java Scheduler.
External schedulers cannot schedule jobs by using the scheduling capabilities of Java Scheduler. They can use the scheduler only for job execution. For scheduling jobs, external schedulers should rely on their own scheduling capabilities.
Logging and Tracing
The NetWeaver Scheduler for Java uses the standard SAP Logging framework to log messages on two levels:
● Job level (job logs)
Logs at job level, or job logs, are logged in the database by every job. The following rules apply for job logs:
○ A job log is always associated with the job instance that logged it. The lifetime of the job log matches the lifetime of the job.
○ The log for a job is deleted when the corresponding job is deleted, for example when the job’s retention period has expired.
○ Job logs are not overwritten by a rolling log write strategy. Logs for jobs which are kept for an indefinite period of time cannot be deleted.
○ You can retrieve a log written by a particular job no matter on which cluster node the job ran, or whether the node where the job ran is still part of the cluster.
● Scheduler level (Java Scheduler logs)
By default, the Java Scheduler logs are logged under the /System/Server category, at SYS_SERVER.
Handling the Size of Job Logs
The Java Scheduler allows you to manage the cumulative job log size in the database. A job has a retention period denoting the number of days that a job log is persisted in the database. To prevent database overflow caused by too many job logs, in the job definition’s deployment descriptors you can configure a job’s retention period. For more information, see Deployment Descriptors.