Performance Notes
The performance of an ABAP program is largely determined by the efficiency of its database accesses. It is therefore worth analyzing your SQL statements closely. To help you to do this, you should use the Performance Trace and Runtime Analysis tools (Test menu in the ABAP Workbench). In particular, the SQL Trace in the Performance Trace shows you which parts of Open SQL statements are processed where, and how long they take.
To understand how SQL statements affect the runtime of ABAP programs, you need to understand the underlying system architecture. The work processes of an application server are logged onto the database system (server) as users (clients) for as long as the SAP System is running. The database management system (DBMS) forms the connection between users and data.
The general structure of a DBMS is as follows:
- A database work process provides a service that database clients can call.
- There are different database services for different tasks, for example, for establishing connections, changing database tables, locking database entries, archiving, and so on.
- There is a large shared memory area, containing the DBMS cache and other resources such as the statement cache, and redo information.
- The database files are stored on a hard disk, and are managed by the file system.
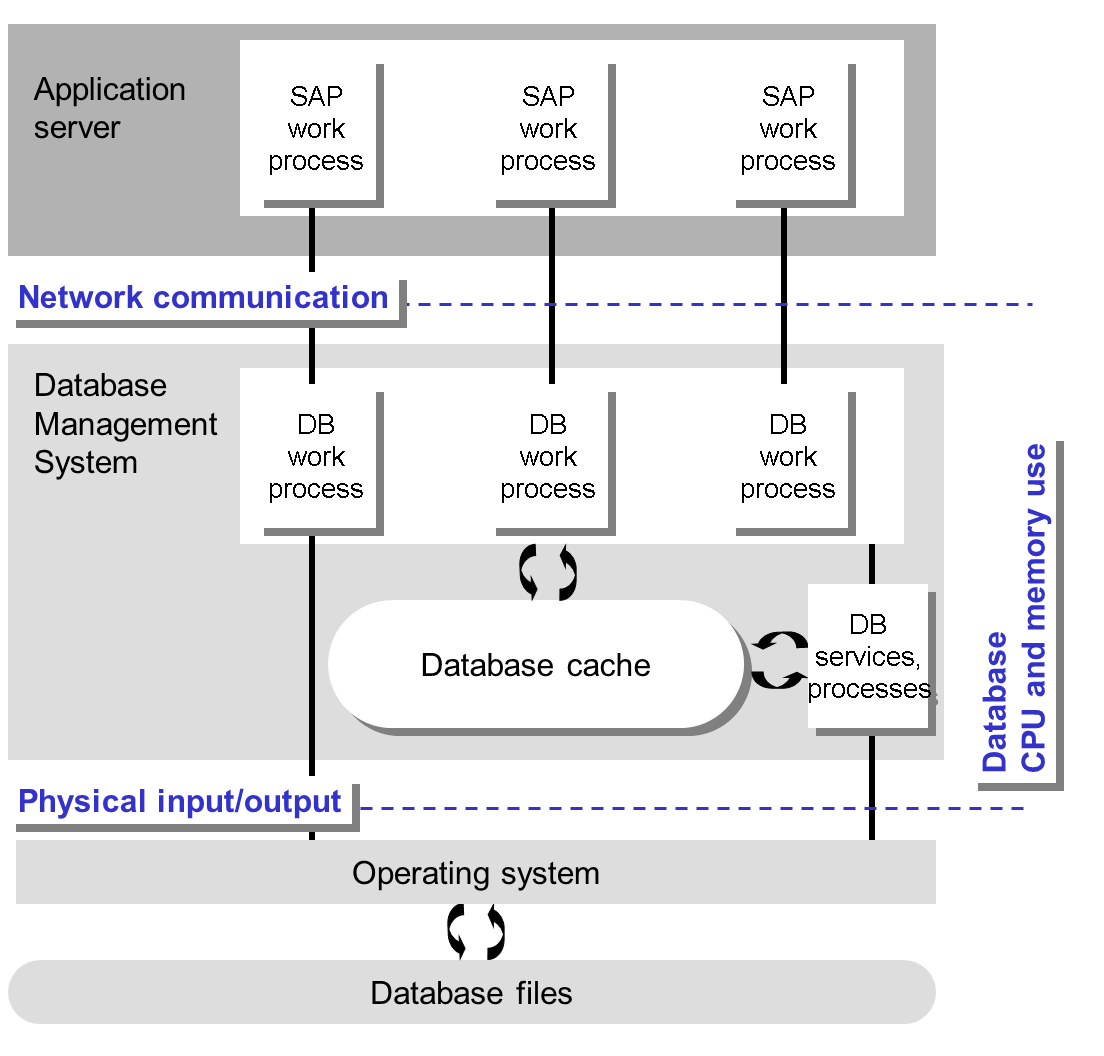
Within this architecture, there are four points that are important in respect of performance:
- Physical input/output (I/O)
Reading and writing database files is the greatest bottleneck. The mark of a well-configured system is the speed of its I/O.
- The memory used by the database cache.
- The CPU usage on the host on which the database is installed.
On a symmetrical multi-processor system, this is irrelevant.
- Network communication
Although unimportant for small data volumes, it becomes a bottleneck when large quantities of data are involved.
Each database system uses an optimizer whose task is to create the execution plan for SQL statements (for example, to determine whether to use an index or table scan). There are two kinds of optimizers:
Rule based
Rule based optimizers analyze the structure of an SQL statement (mainly the SELECT and WHERE clauses without their values) and the table index or indexes. They then use an algorithm to work out which method to use to execute the statement.
Cost based
Cost based optimizers use the above procedure, but also analyze some of the values in the WHERE clause and the table statistics. The statistics contain low and high values of the fields, or a histogram containing the distribution of data in the table. Since the cost based optimizer uses more information about the table, it usually leads to faster database access. Its disadvantage is that the statistics have to be periodically updated.
Use
ORACLE databases up to and including release 7.1 use a rule-based optimizer. As of Release 7.2 (SAP Release 4.0A), they use a cost-based optimizer. All other database systems use a cost-based optimizer.
Based on the above architecture, there are five rules that you should follow to make database accesses in ABAP programs more efficient. They apply in particular to the following database systems:
- ORACLE
- INFORMIX
- ADABAS
- DB2/400 (uses EBCDIC codepage).
- Microsoft SQL Server
For the following database systems, they apply either in part or not at all:
- DB2/6000
- DB2/MVS
- ORACLE Parallel Server (OPS)
The five rules are explained in the following sections:
Minimize the Amount of Data Transferred