
 Datenarchivierung und -löschung im Account
Management (FS-AM)
Datenarchivierung und -löschung im Account
Management (FS-AM) 
Einsatzmöglichkeiten
Mit diesen Prozessen können Sie Daten der implementierten Archivierungs- und Löschobjekte, in denen der Aufbau und die Zusammensetzung der zu archivierenden bzw. zu löschenden Daten festgelegt ist, archivieren bzw. ohne Archivierung aus der Datenbank löschen.
· Beim Archivieren werden die Daten nach verschiedenen Prüfungen auf Archivdateien außerhalb des SAP-Systems repliziert, anschließend Probe gelesen und bei erfolgreicher Archivierung aus der operativen Datenbank entfernt.
· Beim Löschen werden die Daten sofort aus der operativen Datenbank entfernt.
Sowohl die Datenarchivierung als auch die Datenlöschung bietet Ihnen folgende Möglichkeiten:
· Reduzierung der Systembelastung der Server
· Minimierung der Gesamtdatenmenge
· Minimierung der Indexbäume
· Minimierung der Selektionsmengen bei Abfragen
· Optimierung der Pufferauslastung
· Minimierung der Treffermengen
· Vermeidung von Verdrängungsmechanismen
· Minimierung der Netzbelastung
Informationen zu allen Archivierungs- und Löschobjekten des Account Management (FS-AM) finden Sie im Customizing des Account Management in der IMG-Aktivität Technische Dokumentation zum AM. Beim Starten der IMG-Aktivität gelangen Sie in eine Struktur. Dort finden Sie im Abschnitt Konzepte und Richtlinien ® Archivierung ein Überblicksdokument, von dem aus Sie in alle Dokumente der einzelnen Archivierungs- und Löschobjekte navigieren können. Beachten Sie, dass für einige Archivierungsobjekte die Archiving Engine und die Archiving Factory verwendet werden kann bzw. muss.
Voraussetzungen
· Sie haben im Customizing des Account Management unter Archivierung die erforderlichen Einstellungen vorgenommen:
¡ Archivierungsobjektübergreifendes Customizing
¡ Logischen Dateipfad anlegen
¡ Archivierungsobjektspezifisches Customizing
¡ Globale Steuerung der Archivierung pflegen
¡ Globale Steuerung mit Archiving Engine pflegen
· Sie haben im Customizing des Account Management unter Archivierung ® Archivierungsobjekte pro Archivierungsobjekt die zugehörige IMG-Aktivität ausgeführt.
· Sie haben im Customizing des Account Management unter Werkzeuge ® Parallelisierung die IMG-Aktivität Jobverteilung pflegen ausgeführt.
· Sie haben die Berechtigung zum Durchführen des Archivierungsprozesses: Bei allen Aktivitäten wird das Berechtigungsobjekt S_ARCHIVE geprüft.
Ablauf
Der Archivierungsprozess wird über die normale SAP Jobsteuerung eingeplant. Dies kann mit Hilfe der Transaktion SM36 oder der Archivadministration SARA durchgeführt werden. Der Archivierungsprozess ist so konzipiert, dass er parallel zum operativen Betrieb durchgeführt werden kann. Grundsätzlich erfolgt der Archivierungsprozess in den drei Teilprozessen Analyse, Schreiben und Löschen, die im Standard miteinander gekoppelt sind. Die beiden Teilprozesse Analyse und Schreiben werden dabei durch die Nutzung des Parallelisierungstools hochgradig parallelisiert. Dies geschieht durch die Bildung geeigneter Datenpakete, die von verschiedenen Paketverwaltern (Jobs) parallel abgearbeitet werden.
Der Pre-Step ist ein optionaler Teilprozess zur Bildung von Paketprofilen, der ggf. vor der Archivierung durchlaufen werden muss.
Alle Teilprozesse vermerken ihre Aktivitäten im Aktivitätsprotokoll der Archivierung, das mit Hilfe des Monitorprogramms angezeigt werden kann. Das Monitorprogramm ist das zentrale Tool zur Überwachung und Protokollierung von Archivierungsläufen.
1. Pre-Step
Der Teilprozess Pre-Step untersucht vorab den Datenbestand des Archivierungsobjekts und generiert entsprechende Profile, welche die Paketgrenzen für die Parallelverarbeitung festlegen. Die Profile werden persistent auf der Datenbank abgelegt und später – falls im globalen Customizing des Archivierungsobjekts eingestellt – von den Teilprozessen Analyse und Schreiben verwendet.
Ziel bei der Profilgenerierung ist es, die in den Teilprozessen Analyse und Schreiben parallel arbeitenden Paketverwalter gleichmäßig auszulasten, um die Gesamtlaufzeit der Archivierung möglichst niedrig zu halten. Hierzu muss der Datenbestand in disjunkte, möglichst gleich große Pakete unterteilt werden. Da sich im Laufe der Zeit die Verteilung der Daten ändern kann, muss der Pre-Step in regelmäßigen Abständen wiederholt werden, um das Vorhandensein adäquater Profile zu gewährleisten.
Der Pre-Step ist ein optionaler Teilprozess und ist nicht für alle Archivierungsobjekte realisiert.
2. Analyse
Der Teilprozess Analyse untersucht die Daten eines Archivierungsobjekts und ermittelt den Archivierungsstatus sowie ggf. das Wiedervorlagedatum. Dazu werden grundsätzlich zwei Prüfungen durchgeführt:
· Haben die Daten die im Customizing festgelegten Residenzzeiten (Mindestverweildauer der Daten in der operativen Datenbank) erreicht?
· Sind alle betriebswirtschaftlichen Aspekte erfüllt, um die Daten zu archivieren? Dieser Test wird durch einen Prüfbaustein der Applikation realisiert, der seinerseits über Verwendung von BAdIs benutzerdefinierte Prüfungen ermöglicht.
Sind beide Prüfungen erfolgreich, so wird der Archivierungsstatus auf den Wert Archivierbar gesetzt. Im anderen Fall wird der Status auf den Wert Nicht archivierbar und das Wiedervorlagedatum auf den Wert Heutiges Datum + Wiedervorlagezeitraum gesetzt.
A Basisdatum für Archivierung + Residenzzeit + 1 Tag
B Systemdatum + Wiedervorlagezeitraum
Das größere aus A + B wird als Wiedervorlagedatum verwendet
Der Wiedervorlagezeitraum bestimmt die Periodizität der Wiedervorlage nach Ablauf der Residenzzeit und wird im globalen Customizing pro Archivierungsobjekt festgelegt. Dadurch wird gewährleistet, dass die Daten erst nach Ablauf des Wiedervorlagezeitraums erneut analysiert werden, was zur Verringerung der zu bearbeitenden Datenmenge und somit zu einer Zeitersparnis bei der Analyse führt.
Zur weiteren Effizienzsteigerung werden die Daten in disjunkte Pakete aufgeteilt, die durch voneinander unabhängige Jobs analysiert werden. Ein Paket enthält eine durch Schlüsselgrenzen genau definierte Teilmenge der zu verarbeitenden Daten.
Die folgende Abbildung verdeutlicht die durchgeführte Parallelisierung. Mit dem Start der Parallelverarbeitung geht die Kontrolle an das Parallelisierungstool über. Dieses ruft zur Durchführung der einzelnen Prozessteilschritte Callback-Routinen auf, die von der Archivierung für jede Anwendungsart zur Verfügung gestellt werden. Für jedes Archivierungsobjekt gibt es zwei Anwendungsarten, eine für den Teilprozess Analyse und eine für den Teilprozess Schreiben. Die Anzahl der zum Einsatz kommenden Jobs wird für jede Anwendungsart im Customizing der Parallelverarbeitung eingestellt. Jeder Job verarbeitet verschiedene Teilpakete, die er nacheinander aus einem von allen Jobs geteilten Arbeitsvorrat entnimmt.
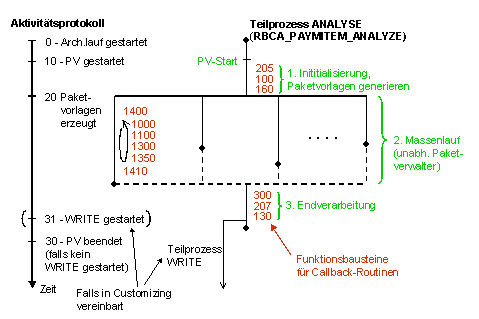
Am linken Rand der Abbildung wird die zeitliche Abfolge der Prozessstatus dargestellt. Im Aktivitätsprotokoll wird immer der aktuellste Status eines Prozesses ausgewiesen. Je nach Customizing-Einstellung gibt es zwei mögliche Endstatus, die einen erfolgreichen Prozessverlauf signalisieren: ‚31’ kennzeichnet, dass automatisch ein Teilprozess WRITE gestartet wurde, während der Eintrag ‚30’ darauf hinweist, dass der Teilprozess Analyse beendet und kein WRITE-Prozess gestartet wurde.
3. Schreiben
Das Schreibprogramm wird im Standard automatisch durch das Analyseprogramm gestartet und repliziert die vom Teilprozess Analyse zuvor gekennzeichneten Daten (Status „Archivierbar“) von der operativen Datenbank in neue Archivdateien. In diesem Schritt findet also die eigentliche Datenarchivierung statt.
Das Schreiben der Daten erfolgt ebenso wie die Analyse parallel in voneinander unabhängigen Jobs (siehe Abbildung). Jeder Job verarbeitet verschiedene Teilpakete, die er aus dem gemeinsamen Arbeitsvorrat entnimmt. Pro Job in der Parallelverarbeitung entsteht immer genau ein Archivierungslauf, der aus einer oder mehreren Archivdateien bestehen kann.
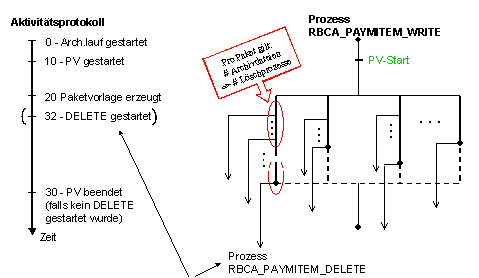
Am linken Rand der Abbildung wird die zeitliche Abfolge der Prozessstatus dargestellt. Im Aktivitätsprotokoll wird immer der aktuellste Status eines Prozesses ausgewiesen. Je nach Customizing-Einstellung gibt es zwei mögliche Endstatus, die einen erfolgreichen Prozessverlauf signalisieren: ‚32’ kennzeichnet, dass automatisch ein Teilprozess DELETE gestartet wurde, während der Eintrag ‚30’ darauf hinweist, dass der Teilprozess Analyse beendet und kein DELETE-Prozess gestartet wurde.
4. Löschen
Nach dem Replizieren der Daten auf die Archivdateien werden diese mit Hilfe des Teilprozess Löschen aus der operativen Datenbank entfernt. Dazu werden die archivierten Daten aus den Archivdateien gelesen und nur bei erfolgreichem Einlesen aus dem Archiv aus der Datenbank gelöscht. Dieses Verfahren garantiert, dass nur solche Daten in der Datenbank entfernt werden, die zuvor ordnungsgemäß archiviert werden konnten.
Hat der Schreibprozess eine einzelne Archivdatei erfolgreich abgeschlossen, so wird im Standard automatisch ein separater Löschprozess gestartet (siehe Bild zum Teilprozess Schreiben). Pro Paket in der Parallelverarbeitung des Schreibprogramms entstehen also in der Regel genau so viele Löschprozesse wie Archivdateien von diesem Paket angelegt wurden.
Falls das Probelesen einer Archivdatei misslingt, bleiben die Daten im operativen System mit dem Status „Archivierbar“ stehen und werden beim Schreibprozess des nächsten Archivierungslaufs erneut verarbeitet. Die bereits angelegten Archivdateien können nach Belieben manuell gelöscht oder auch auf dem Archiv belassen werden. Letzteres ist ungefährlich, da auf die Dateien aus dem operativen System heraus nicht verwiesen wird, weil Archivinfostrukturen nur beim erfolgreichen Abschluss eines Löschvorgangs angelegt werden.
Ergebnis
Erfolgreicher Abschluss
Nach ordnungsgemäßer Durchführung der Archivierung sind die aus betriebswirtschaftlicher und technischer Sicht archivierbaren Daten von der operativen Datenbank in Archivdateien ausgelagert. Sie können mit Hilfe der implementierten sequentiellen Leseprogramme, dem Archivinformationssystem (Transaktion SARI) oder den zugehörigen Business-View(s) am Bildschirm angezeigt werden. Bei einigen Archivierungsobjekten, wie z. B. Konto und Karte, werden die archivierten Daten mit den normalen Anzeigetransaktionen angezeigt.
Rückladen der Daten
Es besteht die Möglichkeit, die archivierten Daten mit Hilfe von Rückladeprogrammen wiederherzustellen. Dabei werden die Daten aus den Archivdateien gelesen und in die operative Datenbank eingefügt. Dies ist jedoch nur im Notfall (falsche Customizing-Einstellungen, technische Probleme) erlaubt. Um einen Missbrauch dieser Funktionalität zu vermeiden und mögliche Inkonsistenzen durch Einbringung alter Daten ins operative System zu verhindern, kann ein Rückladen der Daten nur innerhalb einer Frist von fünf Tagen nach erfolgter Archivierung geschehen. Die Archivinformationsstrukturen werden durch das Rückladen nicht aktualisiert und können vom Benutzer durch die Transaktion SARI explizit neu aufgebaut werden. Das Attribut “Archivstatus” der zurückgeladenen Datensätze wird auf „Nicht archivierbar“ gesetzt, das Wiedervorlagedatum wird nicht angepasst. Achtung: Die zurückgeladenen Datensätze werden mit dem nächsten Archivierungslauf erneut aufs Archiv geschrieben werden. (Sollte dies nicht erwünscht sein, muss ggf. das Customizing der Residenzzeiten geeignet angepasst werden.)
Ablage der Archivdateien
Im Allgemeinen genügt es nicht, die zu archivierenden Daten in Archivdateien zu schreiben und aus der Datenbank zu entfernen. Die Archivdateien selbst müssen sicher aufbewahrt und verwaltet werden, um später bei Bedarf darauf zugreifen zu können. Dazu stehen mehrere Alternativen zur Auswahl:
· HSM-Systeme (Hierarchical Storage Management)
Bei einem HSM-System wird ein unendlich großes Dateisystem simuliert. Dazu wird das Dateisystem, in das archiviert wird, in die Speicherhierarchie des HSM-Systems eingebunden. Es reicht aus, im Customizing der Archivierung den Dateipfad entsprechend zu pflegen. Dabei ist die Kommunikation über SAP ArchiveLink nicht notwendig.
· Ablagesystem über SAP ArchiveLink
Wenn über SAP ArchiveLink ein Ablagesystem eines Drittanbieters angeschlossen ist, wird dieses Ablagesystem am Ende eines erfolgreich beendeten Löschprogramms beauftragt, die abgearbeitete Archivdatei abzulegen.
· Manuelle Verwaltung
Falls die Ablage auf einem Ablagesystem nicht gewünscht ist, können die Archivdateien auch eigenständig von der IT-Abteilung verwaltet werden.