
 Technische Systemlandschaft
Technische Systemlandschaft 
Integration
TREX versorgt SAP-Anwendungen innerhalb wie außerhalb von SAP NetWeaver mit intelligenten Such-, Klassifikations- und Aggegrations-Funktionen. Bei der Installation von SAP NetWeaver kann TREX als Standalone Engine installiert werden, um als Teil eines SAP NetWeaver Szenarios der jeweiligen Anwendung seine Funktionen zur Verfügung zu stellen.
Search and Classification (TREX),  Knowledge
Management (KM) und Search Engine Service
(SES) stellen gemeinsam eine integrierte SAP-Suchtechnologie für die
unternehmensweite Suche in unstrukturierten wie strukturierten Daten
(Dokumentsammlungen/Business-Objekte) zur Verfügung.
Knowledge
Management (KM) und Search Engine Service
(SES) stellen gemeinsam eine integrierte SAP-Suchtechnologie für die
unternehmensweite Suche in unstrukturierten wie strukturierten Daten
(Dokumentsammlungen/Business-Objekte) zur Verfügung.
TREX-Komponenten
Die folgende Graphik zeigt die einzelnen Komponenten und ihre Kommunikation:
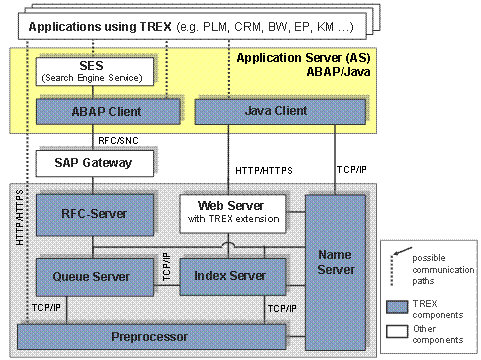
TREX besteht aus folgenden zentralen Komponenten:
● Java-Client und ABAP-Client
TREX bietet Programmierschnittstellen (Application Programming Interfaces, APIs) für die Sprachen Java und ABAP an. Diese Schnittstellen werden auch als Java-Client oder ABAP-Client bezeichnet. Die Schnittstellen ermöglichen den Zugriff auf alle TREX-Funktionen. Mit Hilfe der Schnittstellen ist es möglich, Indizes und Queues anzulegen, zu indizieren und zu suchen. Die Schnittstellen sind Teil des NetWeaver Application Servers (NW AS).
● Web-Server mit TREX-Erweiterung
Der Web-Server ist für die Kommunikation zwischen einer Java-Anwendung und den TREX-Servern zuständig. Auf dem Web-Server ist eine TREX-Komponente installiert, die den Web-Server um TREX-spezifische Funktionen erweitert.
● RFC-Server
Der RFC-Server ist für die Kommunikation zwischen einem SAP-System und den TREX-Servern zuständig. Das SAP-System sendet seine Requests über ein SAP-Gateway an einen RFC-Server. Der RFC-Server wandelt die Requests in ein TREX-internes Format um und leitet sie an den zuständigen TREX-Server weiter.
● Queue-Server
Der Queue-Server koordiniert die Verarbeitungsschritte, die während der Indizierung ablaufen. Er sammelt die eingehenden Dokumente, veranlasst ihre Vorverarbeitung durch den Präprozessor und ihre weitere Verarbeitung durch den Index-Server.
● Präprozessor
Der Präprozessor verarbeitet Dokumente und Suchanfragen vor. Die Vorverarbeitung von Dokumenten besteht mehreren Schritten: Dokument laden, Dokument filtern, Dokument linguistisch analysieren. Bei Suchanfragen führt der Präprozessor eine linguistische Analyse durch.
● Index-Server
Der Index-Server indiziert und klassifiziert Dokumente und beantwortet Suchanfragen. Die Verarbeitung findet in den Engines statt, die zum Index-Server gehören: Suchmaschine, Text-Mining-Engine, Attribut-Engine.
● Name-Server
Der Name-Server verwaltet Informationen über das gesamte TREX-System. Er sorgt dafür, dass die TREX-Server miteinander kommunizieren können und die benötigten Informationen erhalten. Er hat folgende Aufgaben: Topologie-Daten verwalten, Replikationsdienste koordinieren, Last verteilen und Hochverfügbarkeit sicherstellen
Suchmaschinenservice (SES/Search Engine Service)
Der Suchmaschinenservice (SES/Search Engine Service) ermöglicht die Suche nach Business-Objekten. SES ist keine Komponente von TREX, sondern Teil des SAP NetWeaver Application Servers. SES greift über den TREX-ABAP-Client auf die TREX-Funktionen zu.
Weiterführende Informationen
Die folgende Tabelle listet auf, wo Sie weitere Informationen über die technische Systemlandschaft finden können.
Thema |
Guide/Tool |
Quick Link zum SAP Service Marketplace (service.sap.com) |
TREX-Komponenten |
|
|
Technische Konfiguration |
● Installationsleitfaden SAP NetWeaver 7.0 Search and Classification (TREX) Single Host ● Installationsleitfaden SAP NetWeaver 7.0 Search and Classification (TREX) Multiple Hosts |
Weitere Informationen finden Sie auf dem
SAP Service Marketplace unter service.sap.com/ |
Sicherheit |
|
|
Suchmaschinenservice (SES/Search Engine Service) |
|