
 Applikationsserver
Applikationsserver
R/3-Programme laufen auf Applikationsservern ab. Applikationsserver sind also wichtige Softwarekomponenten des R/3-Systems. In den folgenden Abschnitten beschreiben wir die Applikationsserver genauer.
Aufbau eines Applikationsservers
Alle Applikationsserver eines R/3-Systems unter Einbeziehung des Message Servers bilden die Applikationsschicht der mehrstufigen Architektur des R/3-Systems . Die Anwendungsprogramme eines R/3-Systems werden auf den Applikationsservern ausgeführt. Die Applikationsserver kommunizieren dabei mit den Präsentationskomponenten, mit der Datenbank und über den Message Server auch untereinander .
Das folgende Bild zeigt den Aufbau eines Applikationsservers:
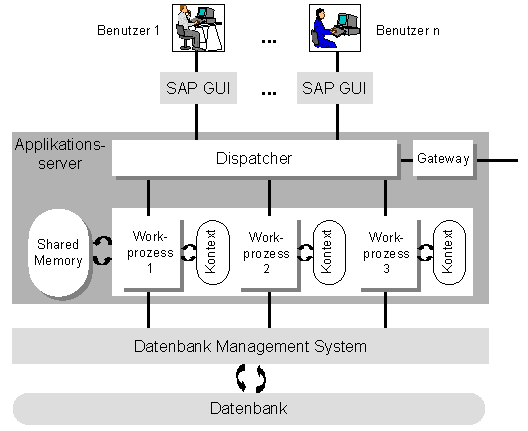
Die einzelnen Komponenten sind:
Workprozesse
Applikationsserver enthalten Workprozesse, deren Anzahl und Typ beim Start des R/3-Systems festgelegt wird. Workprozesse sind Komponenten, die in der Lage sind, eine Anwendung (bzw. jeweils einen Dialogschritt) auszuführen. Jeder Workprozess hat Verbindung zu einem Speicherbereich in dem sich der Kontext der gerade ausgeführten Anwendung befindet. Der Kontext beinhaltet die aktuellen Daten des laufenden Programms und muß für jeden Dialogschritt dieses Programms verfügbar sein. Weiter unten erfahren Sie mehr über die unterschiedlichen Typen von Workprozessen.
Dispatcher
Jeder Applikationserver enthält einen Dispatcher. Der Dispatcher ist das Bindeglied zwischen den Workprozessen und den an dem Applikationsserver angemeldeten Benutzern (bzw. deren SAP GUIs). Seine Aufgabe besteht darin, jedesmal, wenn eine Benutzerinteraktion dazu führt, daß ein Dialogschritt ausgeführt werden soll, diesen Auftrag vom SAP GUI entgegenzunehmen und ihn an einen freien Workprozess weiterzuleiten. Auf dem gleichen Wege gelangen die Bildschirmausgaben, die aus der Ausführung des Dialogschritts resultieren, wieder zum Benutzer zurück.
Gateway
Jeder Applikationserver enthält ein Gateway. Das Gateway ist die Vermittlungsinstanz für die Kommunikationsprotokolle des R/3-Systems (RFC, CPI/C) und kann mit anderen Applikationsservern des gleichen R/3-Systems, mit anderen R/3-Systemen, mit R/2-Systemen oder mit externen (nicht-SAP) Anwendungen kommunizieren.
Der hier beschriebene Aufbau der Applikationsserver unterstützt die Performance und Skalierbarkeit des gesamten R/3-Systems. Die feste Anzahl von Workprozessen und das Dispatching von Dialogschritten auf die Workprozesse sorgen für eine gute Ausnutzung des Hauptspeichers im verwendeten Rechner, da manche Komponenten und Speicherbereiche eines Workprozesses unabhängig von den Anwendungen sind und wiederverwendet werden. Da die einzelnen Workprozesse unabhängig voneinander arbeiten, bieten sie eine optimale Vorraussetzung für Mehrprozessor-Architekturen. Auf die Arbeitsweise des Dispatchers und die Verteilung von anfallenden Aufgaben auf Workprozessen gehen wir im Abschnitt Dispatching von Dialogschritten noch näher ein.
Shared Memory
Alle Workprozesse eines Applikationsservers verwenden einen gemeinsamen Hauptspeicher, das Shared Memory, um Kontexte zu speichern oder um selten geänderte Daten lokal zu puffern.
Im Shared Memory stehen die von allen Workprozessen genutzten Ressourcen (wie Programme oder Tabelleninhalte) zur Verfügung. Die Speicherverwaltung des R/3-Systems sorgt dafür, daß die Workprozesse immer den aktuellen Kontext, d.h. die Datenmengen, die den aktuellen Bearbeitungszustand eines laufenden Programms enthalten, adressieren. Über ein Mapping-Verfahren wird zu diesem Zweck der für die Ausführung eines Dialogschritts erforderliche Kontext aus dem gemeinsamen Hauptspeicher in den Adreßraum des bearbeitenden Workprozessses projeziert. Dadurch sind die tatsächlichen Kopiervorgänge auf ein Minimum reduziert.
Die lokale Pufferung von Daten im Shared Memory des Applikationsservers entlastet die Datenbank, da mehrfaches Lesen vermieden wird. Dadurch verkürzen sich die Zugriffszeiten für die Anwendungsprogramme erheblich. Durch die Konzentration einzelner Anwendungen (Finanzwirtschaft, Logistik, Personalwirtschaft) auf getrennte Applikationsservergruppen kann eine optimale Ausnutzung der Puffer erreicht werden.
Datenbankanbindung
Während des Starts eines R/3-Systems meldet jeder Applikationsserver seine Workprozesse an die Datenbankschicht an und erhält dadurch für jeden Workprozess genau einen fest definierten Kanal. Jeder Workprozess ist für die gesamte Laufzeit des R/3-Systems ein Benutzer (Client) des Datenbanksystems (Server). Während der Laufzeit des Systems erfolgen keine Ummeldungen und ein Datenbank-Kanal kann nicht von einem Workprozess zum anderen weitergereicht werden. Aus diesem Grund kann ein Workprozess Datenbankänderungen immer nur im Rahmen genau einer Datenbank-LUW (Logical Unit of Work) ausführen. Eine Datenbank-LUW ist eine nicht teilbare Folge von Datenbankoperationen. Dies hat wichtige Konsequenzen für das Programmiermodell, auf die wir unten noch näher eingehen.
Dispatching von Dialogschritten
Die Anzahl der Benutzer, die sich an einem Applikationsserver anmelden, ist häufig um ein Vielfaches größer als die Anzahl der zur Verfügung stehenden Workprozesse und nicht durch die Architektur des R/3-System begrenzt. Jeder Benutzer kann wiederum mehrere parallele Anwendungen ausführen. Der Dispatcher hat dabei die wichtige Aufgabe alle anfallenden Dialgschritte auf die Workprozesse des Applikationsservers zu verteilen.
Wie der zeitliche Ablauf des Dispatching aussehen kann, zeigen wir Ihnen am folgenden Beispiel:
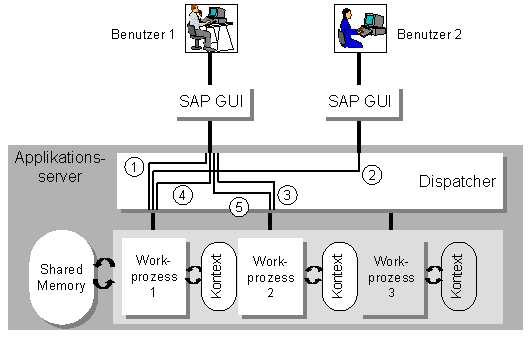
Dem Beispiel entnehmen wir, daß
Aus dem Beispiel geht nicht hervor, daß der Dispatcher die Aufträge so auf die Workprozesse zu verteilen versucht, daß möglichst oft der gleiche Workprozess für aufeinanderfolgende Dialogschritte einer Anwendung verwendet wird. Dadurch kann die Neuadressierung des Programmkontexts im Shared Memory eingespart werden.
Dispatching und Programmiermodell
Nachdem die die Trennung von Anwendungs- und Präsentationsschicht die Aufteilung von Anwendungsprogrammen in Dialogschritte erforderlich machte, führt das im vorhergehenden Abschnitt vorgestellte Dispatching der Dialogschritte auf einzelne Workprozesse zu weiteren wichtigen Konsequenzen für das Programmiermodell.
Wie schon oben erwähnt, kann ein Workprozess Datenbankänderungen immer nur im Rahmen genau einer Datenbank-LUW (Logical Unit of Work) ausführen. Eine Datenbank-LUW ist eine nicht teilbare Folge von Datenbankoperationen an deren Anfang und Ende ein konsistenter Datenbestand auf der Datenbank stehen muß. Anfang und Ende einer Datenbank-LUW werden durch einen Commit-Befehl an das Datenbanksystem definiert (Datenbank-Commit). Während einer Datenbank-LUW, also zwischen zwei Datenbank-Commits, sorgt das Datenbanksystem selbst für die Konsistenz (Widerspruchsfreiheit) des Datenbestands. Das heißt, es übernimmt selbständig Aufgaben wie Datenbankeinträge während ihrer Bearbeitung zu sperren oder den alten Zustand nach einem fehlerhaften Abbruch wiederherzustellen (Rollback).
Typische SAP-Anwendungsprogramme erstrecken sich über einige Bildschirmbilder und die zugehörigen Dialogschritte. Der Benutzer fordert auf den einzelnen Bildschirmen Datenbankänderungen an, die nach Ablauf einer Bildschirmfolge zu einem konsistenten Datenbestand auf der Datenbank führen sollen. Die einzelnen Dialogschritte laufen auf unterschiedlichen Workprozessen und ein einzelner Workprozess bearbeitet nacheinander Dialogschritte unabhängiger Anwendungen. Es ist klar, daß voneinander unabhängige Anwendungen, deren Dialogschritte nacheinander auf einem Workprozess ausgeführt werden, nicht mit der gleichen Datenbank-LUW arbeiten dürfen.
Daraus folgt, daß ein Workprozess für jeden Dialogschritt eine eigene Datenbank-LUW öffnen muß. Der Workprozess sendet also am Ende jedes Dialogschritts, während dem Datenbankänderungen ausgeführt werden, einen Commit-Befehl (Datenbank-Commit) an die Datenbank. Diese Commit-Befehle sind nicht explizit in der Anwendung programmiert und wir nennen sie deshalb implizite Datenbank-Commits.
Durch diesen impliziten Datenbank-Commit wird die Zeit, in der ein Benutzer eine Datenbank-LUW aufrechterhalten kann auf maximal einen Dialogschritt beschränkt. Dies bedeuted eine erhebliche Entlastung der Datenbank, verringert die Häufigkeit von Serialisierungen und Deadlocks und ermöglicht daher eine sehr große Zahl von Benutzern an einem System.
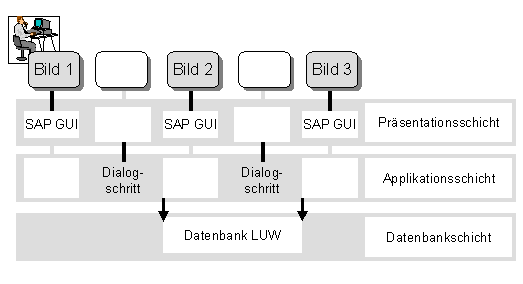
Es stellt sich jetzt die Frage, wie sich die Verknüpfung jedes einzelnen Dialogschritts mit einer Datenbank-LUW mit der Anforderung in Einklang bringen läßt, daß das Festschreiben (Commit) oder Zurücknehmen von Datenbankänderungen (Rollback) vom logischen Ablauf der Anwendungsprogramme abhängen sollte und nicht von der technischen Verteilung auf Dialogschritte. Wenn Aktualisierungsanforderungen voneinander abhängen, bilden sie logische Einheiten im Programmverlauf, die sich über mehrere Dialogschritte erstrecken können. Die Datenbankänderungen solcher logischer Einheiten müssen zusammen ausgeführt und entsprechend auch zusammen zurückgesetzt werden.
Das SAP-Programmiermodell bietet für diese Anforderung eine Reihe von Bündelungstechniken an, die es ermöglichen, daß Datenbankaktualisierungen in solchen logischen Einheiten ablaufen können. Die Teile von R/3-Anwendungsprogramms, die eine logisch zusammengehörende Menge von Datenbank-Operationen bündeln, bezeichnen wir als SAP-LUW. Im Gegensatz zur Datenbank-LUW umfaßt eine SAP-LUW die Gesamtheit der Dialogschritte einer logischen Einheit inklusive der Fortschreibung auf der Datenbank (Verbuchung).