
 Logische Datenbanken und Contexte
Logische Datenbanken und Contexte
Dieser Abschnitt beschreibt führt logische Datenbanken und Contexte ein, die das Lesen von Daten von der Datenbank erleichtern. Bei beiden werden die eigentlichen Open SQL-Anweisungen in eigenen ABAP-Programmen gekapselt.
Logische Datenbanken
Logische Datenbanken sind spezielle ABAP-Programme, die Daten aus Datenbanktabellen lesen und ausführbaren ABAP-Programmen (Typ 1) zur Verfügung stellen. Zur Laufzeit kann man sich logische Datenbank und ausführbares ABAP-Programm als ein einziges ABAP-Programm denken, dessen Verarbeitungsblöcke in bestimmter vorgegebener Reihenfolge von der Laufzeitumgebung aufgerufen werden.
Logische Datenbanken werden mit einen eigenen Tool der ABAP Workbench gepflegt und können mit ausführbaren Programmen bei der Festlegung der Programmattribute verknüpft werden. Eine logische Datenbank kann mit beliebig vielen ausführbaren Programmen verknüpft werden. Seit Release 4.5A können logische Datenbanken auch selbständig aufgerufen werden.
Aufbau einer logischen Datenbank
Den Aufbau einer logischen Datenbank können wir in drei Teile gliedern, die im folgenden Bild dargestellt sind:
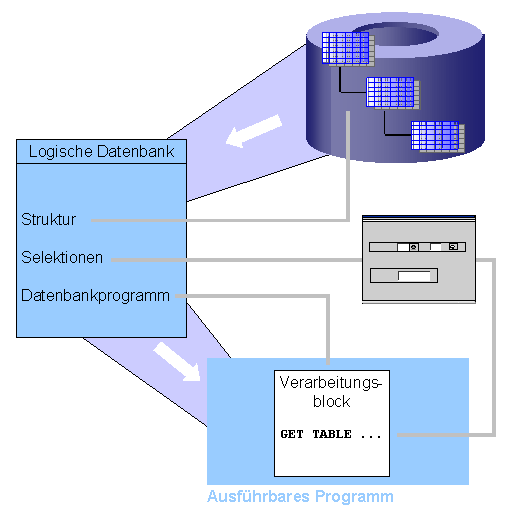
Struktur
Die Struktur legt die Datenbanktabellen legt die Auswahl der Datenbanktabellen fest, auf welche die logische Datenbank zugreifen kann. Sie übernimmt die gegebene Hierarchie der Datenbanktabellen, die durch Fremdschlüsselbeziehungen festgelegt ist und regelt die Reihenfolge des Zugriffs auf mehrere Datenbanktabellen.
Selektionsteil
Der Selektionsteil definiert Eingabefelder für Abgrenzungen in der logischen Datenbank, welche die Laufzeitumgebung zu Beginn des ausführbaren Programms auf dem Selektionsbild zur Anzeige bringt. Die entsprechenden Felder sind auch im ausführbaren ABAP-Programm sichtbar und können dort für eine eventuelle Vorbelegung des Selektionsbilds geändert werden.
Datenbankprogramm
Das Datenbankprogramm einer logischen Datenbank ist ein Container für spezielle Unterprogramme, in denen unter anderem die Daten aus den Datenbanktabellen gelesen werden. Diese Unterprogramme werden vom Reportingprozessor der Laufzeitumgebung in einer von der Struktur vorgebenenen Reihenfolge aufgerufen.
Ausführung von Typ 1-Programmen mit logischer Datenbank
Das folgende Bild zeigt die wichtigsten Verarbeitungsblöcke, die bei der Ausführung eines ausführbaren Programms, das mit einer logischen Datenbank verknüpft ist, aufgerufen werden.

Die Aufrufe der Laufzeitumgebung hängen zum einen von der Struktur der logischen Datenbank und zum anderen von der Definition des ausführbaren Programms ab. Die Struktur der logischen Datenbank bestimmt, in welcher Reihenfolge die Unterprogramme der logischen Datenbank aufgerufen werden, die wiederum GET-Ereignisblöcke im ausführbaren Programm aufrufen. Die im ausführbaren Programm definierten GET-Ereignisblöcke bestimmen die Lesetiefe der logischen Datenbank. TABLES- oder NODES-Anweisungen im Deklarationsteil des ausführbaren Programms bestimmen welche der in der logischen Datenbank definierten Eingabefelder auf dem Selektionsbild aufgenommen werden und definieren Schnittstellen-Arbeitsbereiche für die Datenübergabe zwischen logischer Datenbank und ausführbarem Programm.
Der eigentliche Zugriff auf die Datenbank des R/3-Systems erfolgt über Open SQL-Anweisungen, die in den PUT_<TABLE>-Unterprogrammen programmiert sind. Die eingelesenen Daten werden über die Schnittstellen-Arbeitsbereiche an das ausführbare Programm übergeben. Nach dem Einlesen der Daten im logischen Datenbankprogramm hat das ausführbare Programm die Möglichkeit diese Daten in den GET-Ereignisblöcken zu verarbeiten. Dadurch wird eine Trennung von Datenauslese und Datenverarbeitung erreicht.
Einsatz logischer Datenbanken
Logische Datenbanken dienen primär der Wiederverwendung vordefinierter Funktionalität zum Lesen von Daten aus Datenbanktabellen. SAP liefert zu allen Anwendungen logische Datenbanken aus. Diese Datenbanken sind performanceoptimiert und enthalten weitere Funktionalitäten wie z.B. Berechtigungsprüfungen und Suchhilfen. Der Einsatz von logischen Datenbanken ist dann sinnvoll, wenn die auszulesenden Datenbanktabellen sich weitgehend mit der Struktur der logischen Datenbank decken und der Ablauf des Programms (Datenselektion-Datenauslese-Datenverarbeitung-Datenanzeige) den Anforderungen der Anwendung entspricht.
Contexte
In der Anwendungsprogrammierung werden oft aus wenigen Grunddaten, die z.B. vom Benutzer beim Benutzerdialog eingegeben werden, weitere Daten abgeleitet. Zu diesem Zweck werden entweder die relationalen Beziehungen zwischen Daten in der Datenbank verwendet, um basierend auf den Grunddaten weitere Daten zu lesen, oder man leitet weitere Werte aus den Grunddaten durch ABAP-Anweisungen ab.
Dabei kommt es häufig vor, daß in einem Programm oder sogar über mehrere Programme hinweg bestimmte Beziehungen zwischen Daten immer in der gleichen Form zur Datenbeschaffung verwendet werden. Somit werden die gleichen Datenbankzugriffe oder Berechnungen immer wieder neu ausgeführt, obwohl das Ergebnis im System schon einmal vorhanden war. Dies führt zu einer unnötigen Systembelastung, die durch den Einsatz von Contexten vermindert werden kann.
Contexte werden im Werkzeug Context-Builder der ABAP Workbench definiert. Sie bestehen aus einzugebenden Schlüsselfeldern, aus Beziehungen zwischen diesen Feldern und daraus ableitbaren weiteren Feldern bestehen. Contexte können die abgeleiteten Felder über Fremdschlüsselbeziehungen zwischen Tabellen, über Funktionsbausteine oder aus anderen Contexten beziehen.

In einem Anwendungs-Programm arbeitet man mit den Instanzen eines Contexts. Es können mehrere Instanzen zu einem Context verwendet werden. Das Anwendungs-Programm versorgt mit der Anweisung SUPPLY die Instanzen von Contexten mit Eingabewerten für die Schlüsselfelder und kann mit der Anweisung DEMAND die abhängigen Felder aus den Instanzen von Contexten abfragen.
Zu jedem Context gehört ein transaktionsübergreifender Puffer auf dem Anwendungsserver. Bei der Abfrage einer Instanz nach Werten sucht das Context-Programm zuerst im zugehörigen Puffer nach einem Datensatz mit den entsprechenden Schlüsselfeldern. Falls vorhanden, wird die Instanz mit diesen Daten versorgt, ansonsten leitet das Context-Programm die abhängigen Daten aus den eingegebenen Schlüsselfeldern ab und schreibt den Datensatz in den Puffer.