
 Extrakt auslesen
Extrakt auslesen
Ähnlich wie bei der Schleifenverarbeitung interner Tabellen können die Daten eines Extraktdatenbestands über eine
Schleife ausgelesen werden:LOOP.
...
[AT FIRST | AT <fgi> [WITH <fgj>] | AT LAST.
...
ENDAT.]
...
ENDLOOP.
Mit der Anweisung LOOP wird die Erzeugung des Extraktdatenbestands eines Programms abgeschlossen und eine Schleife über seine sämtlichen Sätze ausgeführt. Es wird pro Schleifendurchlauf ein Extraktdatensatz eingelesen. Die Werte der extrahierten Daten werden innerhalb der Schleife direkt in die Ausgangsfelder zurückgestellt. Es können mehrere Schleifen hintereinander ausgeführt werden. Die Schleife über einen Extraktdatenbestand ist nicht schachtelbar. Weiterhin können innerhalb und nach der Schleife keine weiteren EXTRACT-Anweisungen verwendet werden. In beiden Fällen kommt es zum Laufzeitfehler.
Im Unterschied zu internen Tabellen wird bei Extraktdatenbeständen also kein spezieller Arbeitsbereich oder ein Feldsymbol als Schnittstelle benötigt. Für jeden gelesenen Satz können die eingelesenen Daten innerhalb der Schleife unter ihren ursprünglichen Feldnamen weiterverarbeitet werden.
Schleifensteuerung
Um verschiedene Anweisungen nur für bestimmte Sätze des Datenbestands auszuführen, kann man die Steueranweisungen AT und ENDAT verwenden.
Die Anweisungsblöcke zwischen den Steueranweisungen werden für die unterschiedlichen Argumente von AT wie folgt abgearbeitet:
Der Anweisungsblock wird einmal beim ersten Satz des Datenbestands ausgeführt
Der Anweisungsblock wird dann abgearbeitet, wenn die Satzart des aktuellen eingelesenen Extraktsatzes durch die Feldgruppe <fg
Der Anweisungsblock wird einmal beim letzten Satz des Datenbestands ausgeführt
Die Steueranweisungen AT und ENDAT können auch zur
Gruppenstufenverarbeitung eingesetzt werden.
Das folgende Programm sei mit der
REPORT demo_extract_loop.
NODES: spfli, sflight.
FIELD-GROUPS: header, flight_info, flight_date.
INSERT: spfli-carrid spfli-connid sflight-fldate
INTO header,
spfli-cityfrom spfli-cityto
INTO flight_info.
START-OF-SELECTION.
GET spfli.
EXTRACT flight_info.
GET sflight.
EXTRACT flight_date.
END-OF-SELECTION.
LOOP.
AT FIRST.
WRITE / 'Start of LOOP'.
ULINE.
ENDAT.
AT flight_info WITH flight_date.
WRITE: / 'Info:',
spfli-carrid , spfli-connid, sflight-fldate,
spfli-cityfrom, spfli-cityto.
ENDAT.
AT flight_date.
WRITE: / 'Date:',
spfli-carrid , spfli-connid, sflight-fldate.
ENDAT.
AT LAST.
ULINE.
WRITE / 'End of LOOP'.
ENDAT.
ENDLOOP.
Das Anlegen und Füllen des Extraktdatenbestands entspricht dem Beispiel unter
Extrakt mit Daten füllen. Zum Zeitpunkt END-OF-SELECTION ist die Datenbeschaffung durch die logische Datenbank abgeschlossen und der Datenbestand wird in der LOOP-Schleife einmal gelesen.Durch die Steueranweisungen AT FIRST und AT LAST werden zu Beginn und Ende der Schleife jeweils eine Zeile und eine Linie in die Liste geschrieben.
Durch die Steueranweisung AT <fg
i > werden für jede der beiden Satzarten die entsprechenden Felder ausgegeben. Durch den Zusatz WITH FLIGHT_DATE werden die Sätze der Feldgruppe FLIGHT_INFO nur dann ausgegeben, wenn danach mindestens ein Satz der Feldgruppe FLIGHT_DATE kommt, also wenn die logische Datenbank zu einem Flug mindestens ein Datum übergeben hat.Der Anfang der Ausgabeliste sieht etwa folgendermaßen aus:
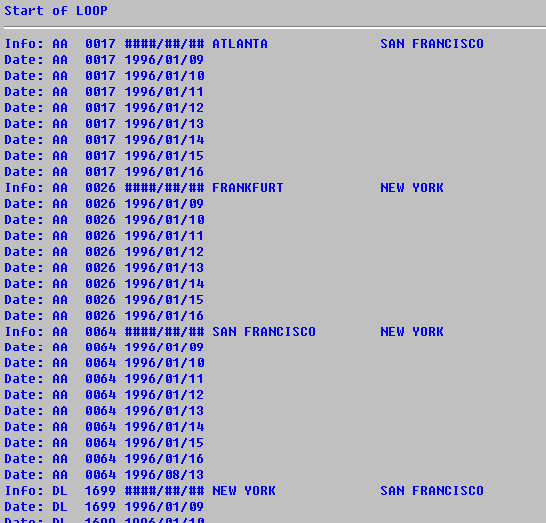
Daß der Inhalt des Felds SFLIGHT-FLDATE im Bereich HEADER der Satzart FLIGHT_INFO auf der Liste als Gatter (#) dargestellt ist, liegt daran, daß die logische Datenbank am Ende einer Hierarchiestufe alle Felder dieser Stufe mit HEX-Nullwerten füllt. Diese Eigenschaft ist wichtig für das Sortieren und die
Gruppenstufenverarbeitung von Extraktdatenbeständen.