Reading Data Objects From Cluster Databases
To read data objects from an ABAP cluster database into an ABAP program, use the following statement:
Syntax
IMPORT <f1> [TO <g
1>] <f
2> [TO <g
2>] ...
FROM DATABASE <dbtab>(<ar>)
[CLIENT <cli>] ID <key>|MAJOR-ID <maid> [MINOR-ID <miid>].
This statement reads the data objects specified in the list from a cluster in the database <dbtab>. You must declare <dbtab> using a TABLES statement. If you do not use the TO <g
i > option, the data object <f i > in the database is assigned to the data object in the program with the same name. If you do use the option, the data object <f i > is read from the database into the field <g i >.To save a data cluster in a database, use the EXPORT TO DATABASE statement (refer to
Saving Data Objects in a Cluster Database). For information about the structure of the database table <dbtab>, refer to the section Structure of Cluster Databases.For <ar>, enter the two-character area ID for the cluster in the database. The name <key> identifies the data in the database. Its maximum length depends on the length of the name field in <dbtab>. You can replace the ID <key> addition with MAJOR-ID <maid>. The system then selects the data cluster whose name corresponds to <maid>. If you also use the MINOR-ID <miid> addition, the system searches for the data cluster whose name is greater than or equal to <miid> starting at the position following the length of <maid>. The CLIENT <cli> option allows you to disable the automatic client handling of a client-specific cluster database, and specify the client yourself. The addition must always come directly after the name of the database.
The IMPORT statement also reads the contents of the user fields from the database table.
You do not have to read all of the objects stored under a particular name <key>. You can restrict the number of objects by specifying their names. If the database does not contain any objects that correspond to the key <ar>, <key>, and <cli>, SY-SUBRC is set to 4. If, on the other hand, there is a data cluster in the database with the same key, SY-SUBRC is always 0, regardless of whether it contained the data object <f
i >. If the cluster does not contain the data object <f i >, the target field remains unchanged.In this statement, the system does not check whether the structure of the object in the database is compatible with the structure into which you are reading it. If this is not the case, a runtime error occurs. Exceptions are fields with type C, which may occur at the end of a structured data object. These can be extended, shortened, added, or omitted.

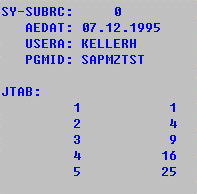
PROGRAM SAPMZTS3.
TABLES INDX.
DATA: BEGIN OF JTAB OCCURS 100,
COL1 TYPE I,
COL2 TYPE I,
END OF JTAB.
IMPORT ITAB TO JTAB FROM DATABASE INDX(HK) ID 'Table'.
WRITE: / 'AEDAT:', INDX-AEDAT,
/ 'USERA:', INDX-USERA,
/ 'PGMID:', INDX-PGMID.
SKIP.
WRITE 'JTAB:'.
LOOP AT JTAB FROM 1 TO 5.
WRITE: / JTAB-COL1, JTAB-COL2.
ENDLOOP.
This example is based on the example program in the section