Python Machine Learning Client for SAP HANA

Welcome to Python machine learning client for SAP HANA (hana-ml)!
This package enables Python data scientists to access SAP HANA data and build various machine learning models using the data directly in SAP HANA. This page provides an overview of hana-ml.
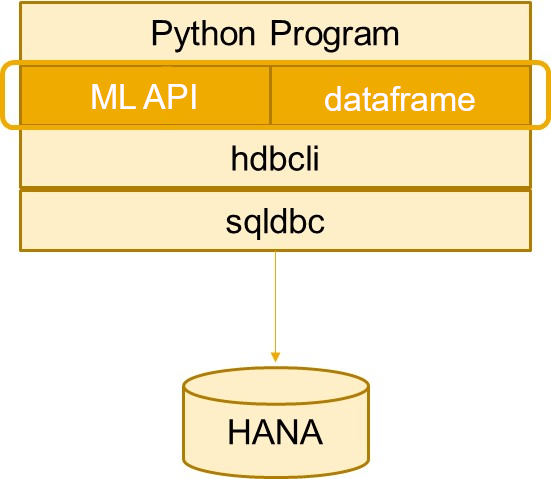
Python machine learning client for SAP HANA consists of two main parts:
SAP HANA DataFrame, which provides a set of methods for accessing and querying data in SAP HANA without bringing the data to the client.
A set of machine learning APIs for developing machine learning models.
Specifically, machine learning APIs are composed of two packages:
PAL package
PAL package consists of a set of Python algorithms and functions which provides access to machine learning capabilities in SAP HANA Predictive Analysis Library(PAL). SAP HANA PAL functions cover a variety of machine learning algorithms for training a model and then the trained model is used for scoring.
APL package
Automated Predictive Library (APL) package exposes the data mining capabilities of the Automated Analytics engine in SAP HANA through a set of functions. These functions develop a predictive modeling process that analysts can use to answer simple questions on their customer datasets stored in SAP HANA.
hana-ml uses SAP HANA Python driver (hdbcli) to connect to and access SAP HANA.
A figure of architecture is shown below:
Prerequisites
SAP HANA Python driver: hdbcli 2.2.23 (shipped with SAP HANA SP03) or higher. See SAP HANA Client Interface Programming Reference for SAP HANA Service for more information.
SAP HANA PAL: Security AFL__SYS_AFL_AFLPAL_EXECUTE and AFL__SYS_AFL_AFLPAL_EXECUTE_WITH_GRANT_OPTION roles. See SAP HANA Predictive Analysis Library for more information.
SAP HANA APL 1905 or higher. See SAP HANA Automated Predictive Library Developer Guide for more information. Only valid when using the APL package.
SAP HANA DataFrame
A SAP HANA DataFrame provides a way to view the data stored in SAP HANA without containing any of the physical data. hana-ml makes use of a SAP HANA DataFrame as the input for training and scoring purposes.
A SAP HANA DataFrame hides the underlying SQL statement, providing users with a Python interface to SAP HANA data.
To use a SAP HANA DataFrame, please firstly create a "ConnectionContext" object (a connection to SAP HANA), and then use the methods provided in the library to create a SAP HANA DataFrame. SAP HANA DataFrame is only usable while the connection is open, and is inaccessible once the connection is closed.
The example below shows how to create a "ConnectionContext" object cc and then invoke a method table() to create a simple SAP HANA DataFrame df:
with ConnectionContext('address', port, 'user', 'password') as cc:
df = (cc.table(table='MY_TABLE', schema='MY_SCHEMA').filter('COL3 > 5').select('COL1','COL2'))
More complex dataframes can also be created by applying a sql() method, for example:
df = cc.sql('SELECT T.A, T2.B FROM T, T2 WHERE T.C=T2.C')
Once df (a SAP HANA DataFrame object) is created, there are several types of functions can be executed on the SAP HANA DataFrame object:
DataFrame Manipulation Functions: manipulate the rows and columns of data, such as casting columns into new type(cast()), dropping columns(drop()), filling null values(fillna()), joining dataframes(join()), sorting dataframes(sort()), and renaming columns(rename_columns()).
Descriptive Functions: statistics relating to the data. For example, showing distinct values(distinct()), and creating dataframes with top n values(head()).
DataFrame Transformation Functions: such as copy a SAP HANA DataFrame to a Pandas DataFrame(collect()) and upload the data from a Pandas DataFrame into a SAP HANA database and returns a SAP HANA DataFrame(create_dataframe_from_pandas()).
Remember, a SAP HANA DataFrame is a way to view the data stored within SAP HANA, and does not contain any data. If you want to use other Python libraries on the client along with a SAP HANA DataFrame, you need to convert that SAP HANA DataFrame to be a Pandas DataFrame using collect() function. For example, we could convert a SAP HANA DataFrame df to be a Pandas DataFrame as follows.
pandas_df = df.collect()
Following is a sketch of all the available methods for SAP HANA DataFrame:
Methods
Adds a new column with constant value. |
|
Returns a new SAP HANA DataFrame with a added <id_col> column. |
|
Returns a SAP HANA DataFrame with the group_by column along with the aggregates. |
|
Returns a new SAP HANA DataFrame with an alias set. |
|
Returns a DataFrame with the original columns as well as bin assignments. |
|
Returns a DataFrame with columns cast to a new type. |
|
Copies the current DataFrame to a new Pandas DataFrame. |
|
Returns a new DataFrame with splitted column. |
|
Returns a DataFrame that gives the correlation coefficient between two numeric columns. |
|
Computes the number of rows in the SAP HANA DataFrame. |
|
Declares whether this DataFrame makes use of local temporary tables. |
|
Returns a DataFrame that contains various statistics for the requested column(s). |
|
Returns a new DataFrame without columns derived from the current DataFrame. |
|
Returns a new SAP HANA DataFrame with differenced values. |
|
Disable the column validation. |
|
Returns a new SAP HANA DataFrame with distinct values for the specified columns. |
|
Returns a new SAP HANA DataFrame without the specified columns. |
|
Returns a new SAP HANA DataFrame with duplicate rows removed. |
|
Returns a new DataFrame with NULLs removed. |
|
Returns a sequence of tuples describing the DataFrame's SQL types. |
|
Returns True if this DataFrame has 0 rows. |
|
Enable the column validation. |
|
Returns a DataFrame with NULLs replaced with a specified value. |
|
Selects rows that match the given condition. |
|
Add additional features to the existing dataframe using agg_func and trans_func. |
|
Generates a SAP HANA table type based on the dtypes function of the DataFrame. |
|
Returns dict format table structure. |
|
Returns True if a column is in the DataFrame. |
|
Returns True if a DataFrame contains NULLs. |
|
Returns a DataFrame of the first |
|
Returns True if the column(s) in the DataFrame are numeric. |
|
Returns a new DataFrame that is a join of the current DataFrame with another specified DataFrame. |
|
Gets the maximum value of the columns. |
|
Gets the mean value of the columns. |
|
Gets the median value of the columns. |
|
Gets the minimum value of the columns. |
|
Replace certain value with NULL value. |
|
Returns a DataFrame that gives the pivoted table. |
|
Utility function to generate a new dataframe with [key, features, label] for non time-series dataset and [key, label, features] for time-series dataset. |
|
Returns a DataFrame with renamed columns. |
|
Returns a new DataFrame with replaced value. |
|
Creates a table or view holding the current DataFrame's data. |
|
Materializes dataframe to a SAP HANA native disk. |
|
Returns a new DataFrame with columns derived from the current DataFrame. |
|
Sets the DataFrame using the existing columns. |
|
Sets the name of the DataFrame. |
|
Specifies the source table for the current dataframe. |
|
Returns a new DataFrame sorted by the specified columns. |
|
Returns a new DataFrame sorted by the index. |
|
Returns a new DataFrame sorted by the specified columns. |
|
Returns a new DataFrame with splitted column. |
|
Gets the stddev value of the columns. |
|
Gets the summation of the columns. |
|
Returns a DataFrame of the last |
|
Converts target columns to the specified date format. |
|
Returns a DataFrame with specified column as the first item in the projection. |
|
Pickle object to file. |
|
Returns a DataFrame with specified column as the last item in the projection. |
|
Combines this DataFrame's rows and another DataFrame's rows into one DataFrame. |
|
Gets the value counts of the columns. |
For more details, please refer to hana_ml.dataframe.DataFrame.
Machine Learning API
Machine Learning API is a set of SAP HANA machine learning algorithms.
APL package contains algorithms below:
classification (Gradient Boosting Classifier, Auto Classifier).
clustering (Auto Supervised Clustering, Auto Unsupervised Clustering).
regression (Gradient Boosting Regressor, Auto Regressor).
time series (Auto Time Series).
PAL package contains algorithms below:
abc_analysis (ABC analysis).
association (Apriori, FPGrowth, K-Optimal Rule Discovery(KORD), Sequential Pattern Mining(SPM)).
clustering (Affinity Propagation, Agglomerate Hierarchical Clustering, DBSCAN, Geometry DBSCAN, K-Means, K-Medians, K-Medoids, SlightSilhouette).
crf (Conditional Random Field).
decomposition (Latent Dirichlet Allocation, Principal Component Analysis(PCA)).
discriminant_analysis (Linear Discriminant Analysis).
kernel_density (KDE/Kernel Density Estimation)
linear_model (Linear Regression, Logistic Regression).
linkpred (Link Prediction).
metric functions (AUC, confusion matrix, multiclass AUC, r2_score, accuracy_score).
mixture (Gaussian Mixture).
naive bayes (Naive Bayes).
neighborbhood-based algorithms (K-Nearest Neighbors Classifier/Regressor).
neural_network (Multi-Layer Perceptron Classifier/Regressor).
pagerank (Page Rank).
partition (train_test_val_split function).
preprocessing (Feature Normalizer, Feature Selection, K-bins Discretizer, Missing Value Handling(Imputer), Multidimensional Scaling(MDS), Synthetic Minority Over-Sampling Technique(SMOTE), SMOTETomek, TomenkLinks, Sampling, Variance Test, ImputeTS, IsolationForest).
random distribution sampling functions (bernoulli, beta, binomial, cauchy, chi_squared, exponential, extreme_value, f, gamma, geometric, gumbel, lognormal, negative_binomial, normal, pert, poisson, student_t, uniform, weibull, multinomial).
recommender system algorithms (Alternating Least Square(ALS), Factorized Polynomial Regression Models(FRM), Field-aware Factorization Machine).
regression (Bi-Variate Geometric Regression, Bi-Variate Natural Logarithmic Regression, Cox Proportional Hazard Model, Exponential Regression, Generalised Linear Models(GLM), Polynomial Regression).
som (Self-organizing feature maps).
statistics functions (analysis of variance functions(Anova), chi-squared test functions, condition index, Cumulative Distribution Function(cdf), Distribution fitting, Distribution Quantile, Entropy, Equal Variance Test, Factor Analysis, Grubbs' Test, Kaplan-Meier Survival Analysis, univariate/multivariate analysis functions, One-Sample Median Test, Wilcox Signed Rank Test, t-test functions Inter-Quartile Range (IQR)).
svm (Support Vector Classification, Support Vector Regression, Support Vector Ranking, and one class SVM).
trees (Decision Tree Classifier/Regressor, Random Decision Tree Classifier/Regressor, Gradient Boosting Classifier/Regressor, Hybrid Gradient Boosting Classifier/Regressor).
tsne (T-distributed Stochastic Neighbour Embedding)
time series (ARIMA, Auto ARIMA, Change-Point Detection, FFT, Seasonal Decompose, Trend Test, White Noise Test, Single/Double/Triple/Auto/Brown exponential Smoothing, Croston's Method/Croston TSB, Linear Regression with Damped Trend and Seasonal Adjust, Additive Model Forecast, fast DTW, Hierarchical Forecast, Correlation Function, online ARIMA, Vector ARIMA, LSTM, time series outlier detection ...).
pipeline (run SAP HANA PAL functions in a chain)
unified_classification
unified_clustering
unified_regression
unified_exponentialsmoothing
wst (weighted score table)
cross validation (Decision Tree Classifier/Regressor, Gradient Boosting Classifier/Regressor, Hybrid Gradient Boosting Classifier/Regressor, Generalised Linear Models(GLM), Naive Bayes, Linear Regression, Logistic Regression Multi-Layer Perceptron Classifier/Regressor, Support Vector Machines functions, K-Nearest Neighbors Classifier/Regressor, Alternating Least Square(ALS), Factorized Polynomial Regression Models(FRM), Polynomial Regression).
These client-side Python functions require a SAP HANA DataFrame and parameters as inputs in order to train a model. While Python Machine Learning APIs can invoke SQL functions, the actual model training and scoring is executed in SAP HANA, so no data is brought to the client for training the model. Data movement from the server to the client (or vice versa) is avoided, resulting in faster and better performance.
Here is a simple example for using these machine learning functions:
Note
Some of these parameters are optional and depend on the specific algorithm being used.
Create an instance of the class (for the algorithm you want to use) and pass over the algorithm parameters.
The example below shows how to create an instance 'dtc' of a DecisionTreeClassifier class, pass parameters that specify the type of decision tree (in this case, C4.5), with minimum records of parent as 2, minimum records in leaf as 1, model to be kept as a JSON format, a thread ratio of 0.4, and a split threshold of 1e-5.
dtc = DecisionTreeClassifier(algorithm='c45', min_records_of_parent=2, min_records_of_leaf=1, thread_ratio=0.4, split_threshold=1e-5, model_format='json')
Invoke fit() method of 'dtc' on the DataFrame df_fit (containing the training data) along with the features to be used and the other parameters needed to relate to the data.
dtc.fit(data=df_fit, features=['OUTLOOK', 'TEMP', 'HUMIDITY', 'WINDY'], label='LABEL')
The output from fit() method invocates results in a trained model returned as a property of 'dtc'. Statistics are also returned as a property of the algorithm object dtc. Then, you can invoke the predict() method on 'dtc', passing the DataFrame df2 to the method for prediction. In addition to the df_predict, other parameters can be optionally passed (e.g. verbose output).
result = dtc.predict(data=df_predict, key='ID', verbose=False)
End-to-End Example: Using SAP HANA Predictive Analysis Library (PAL) Module
Here is an example where a UnifiedClassification model is trained with data from a SAP HANA table:
#Step 1: Import related modules.
from hana_ml import dataframe
from hana_ml.algorithms.pal.unified_classification import UnifiedClassification
#Step 2: Create a ConnectionContext object.
conn = dataframe.ConnectionContext('<address>', <port>, '<user>', '<password>')
#Step 3: Create a SAP HANA DataFrame df_fit and point to a table "DATA_TBL_FIT".
df_fit = conn.table(table="DATA_TBL_FIT")
#Step 4: Inspect df_fit.
df_fit.head(6).collect()
OUTLOOK TEMP HUMIDITY WINDY CLASS
0 Sunny 75 70.0 Yes Play
1 Sunny 80 90.0 Yes Do not Play
2 Sunny 85 91.0 No Do not Play
3 Sunny 72 95.0 No Do not Play
4 Sunny 73 70.0 No Play
5 Overcast 72 90.0 Yes Play
#Step 5: Create an UnifiedClassification instance and specify the parameters.
rdt_params = dict(random_state=2,
split_threshold=1e-7,
min_samples_leaf=1,
n_estimators=10,
max_depth=55)
uc_rdt = UnifiedClassification(func='RandomDecisionTree', **rdt_params)
#Step 6: Invoke the `fit()` method and inspect one of returned a attribute importance_.
uc_rdt.fit(data=df_fit, partition_method='stratified',
stratified_column='CLASS', partition_random_state=2,
training_percent=0.7, ntiles=2)
uc_rdt.importance_.collect()
VARIABLE_NAME IMPORTANCE
0 OUTLOOK 0.182848
1 TEMP 0.329288
2 HUMIDITY 0.487864
3 WINDY 0.000000
#Step 7: Create a SAP HANA DataFrame df_predict and point to a table "DATA_TBL_PREDICT".
df_predict = conn.table(table="DATA_TBL_PREDICT")
#Step 8: Preview df_predict.
df_predict.collect()
ID OUTLOOK TEMP HUMIDITY WINDY
0 0 Overcast 75.0 -10000.0 Yes
1 1 Rain 78.0 70.0 Yes
2 2 Sunny -10000.0 NaN Yes
3 3 Sunny 69.0 70.0 Yes
4 4 Rain NaN 70.0 Yes
5 5 None 70.0 70.0 Yes
6 6 *** 70.0 70.0 Yes
#Step 9: Invoke the `predict()` method and inspect the result.
result = uc_rdt.predict(df_predict, key = "ID", top_k_attributions=10)
result.collect()
ID SCORE CONFIDENCE
0 0 Play 1.0
1 1 Play 1.0
2 2 Play 0.6
3 3 Play 1.0
4 4 Play 1.0
5 5 Play 0.8
6 6 Play 0.8
#Step 10: Create a SAP HANA DataFrame df_score and point to a "DATA_TBL_SCORE" Table.
df_score = conn.table(table="DATA_TBL_SCORE")
#Step 11: Preview df_score.
df_score.collect()
ID OUTLOOK TEMP HUMIDITY WINDY CLASS
0 0 Overcast 75.0 -10000.0 Yes Play
1 1 Rain 78.0 70.0 Yes Play
2 2 Sunny -10000.0 NaN Yes Do not Play
3 3 Sunny 69.0 70.0 Yes Do not Play
4 4 Rain NaN 70.0 Yes Play
5 5 None 70.0 70.0 Yes Do not Play
6 6 *** 70.0 70.0 Yes Play
#Step 12: Perform the score method and inspect the result.
score_res = (uc_rdt.score(data=df_score,
key='ID',
max_result_num=2,
ntiles=2,
attribution_method='tree-shap')[1])
score_res.head(4).collect()
STAT_NAME STAT_VALUE CLASS_NAME
0 AUC 0.6938775510204082 None
1 RECALL 0 Do not Play
2 PRECISION 0 Do not Play
3 F1_SCORE 0 Do not Play
#Step 13: Close the connection to SAP HANA.
conn.close()
End-to-End Example: Using SAP HANA Automated Predictive Library (APL) Module
The following example shows how Python machine learning client for SAP HANA can be used in a Jupyter notebook. This example shows how to build and apply a predictive model to detect fraud.
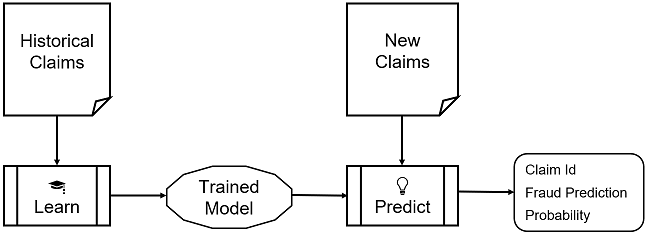
Import the sample data included with the APL package to SAP HANA database.
# Connect using the HANA secure user store
from hana_ml import dataframe as hd
conn = hd.ConnectionContext(userkey='MLMDA_KEY')
sql_cmd = 'SELECT * FROM "APL_SAMPLES"."AUTO_CLAIMS_FRAUD" ORDER BY CLAIM_ID'
hdf_train = hd.DataFrame(conn, sql_cmd)
hdf_train.head(5).collect()

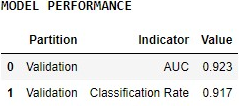
Train a classification model on historical claims data with known fraud and display performance metrics of the trained model.
# Create and train model
from hana_ml.algorithms.apl.gradient_boosting_classification import GradientBoostingBinaryClassifier
apl_model = GradientBoostingBinaryClassifier(variable_auto_selection=True)
apl_model.fit(hdf_train, label='IS_FRAUD', key='CLAIM_ID')
print('\x1b[1m'+ 'MODEL PERFORMANCE' + '\x1b[0m')
sql_where = "\"Partition\"='Validation' and \"Indicator\" in ('AUC','Classification Rate')"
df = apl_model.get_debrief_report('ClassificationRegression_Performance').filter(sql_where).collect()
df = df[['Partition','Indicator','Value']]
df
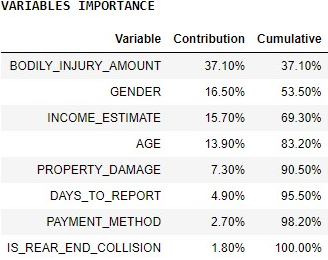
Check how each variable contributes to the prediction.
print('\x1b[1m'+ 'VARIABLES IMPORTANCE' + '\x1b[0m')
df = apl_model.get_debrief_report('ClassificationRegression_VariablesContribution').collect()
df = df.drop(columns=['Oid', 'Rank','Method'])
df = df[(df['Contribution'] > 0)]
format_dict = {'Contribution':'{0:,.2%}','Cumulative':'{0:,.2%}'}
df.sort_values(by=['Contribution'], ascending=False).style.format(format_dict).hide_index()
Alternatively, see the contributions on a bar chart.
import matplotlib.pyplot as plt
c_title = "Relative Contribution"
df = df.sort_values(by=['Contribution'], ascending=True)
df.plot(kind='barh', x='Variable', y='Contribution', title=c_title, legend=False, fontsize=12)
plt.show()
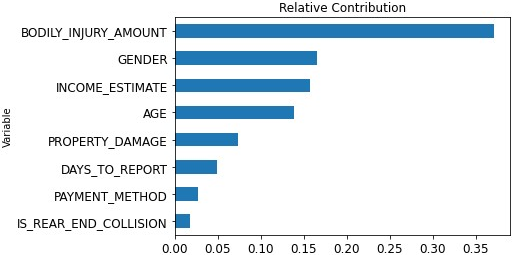
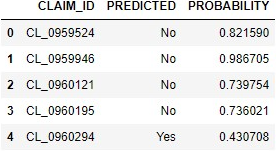
Predict if each new claim is fraudulent or not.
hdf_apply = conn.table(table='AUTO_CLAIMS_NEW', schema='APL_SAMPLES')
df = apl_model.predict(hdf_apply).collect()
df.head(5)
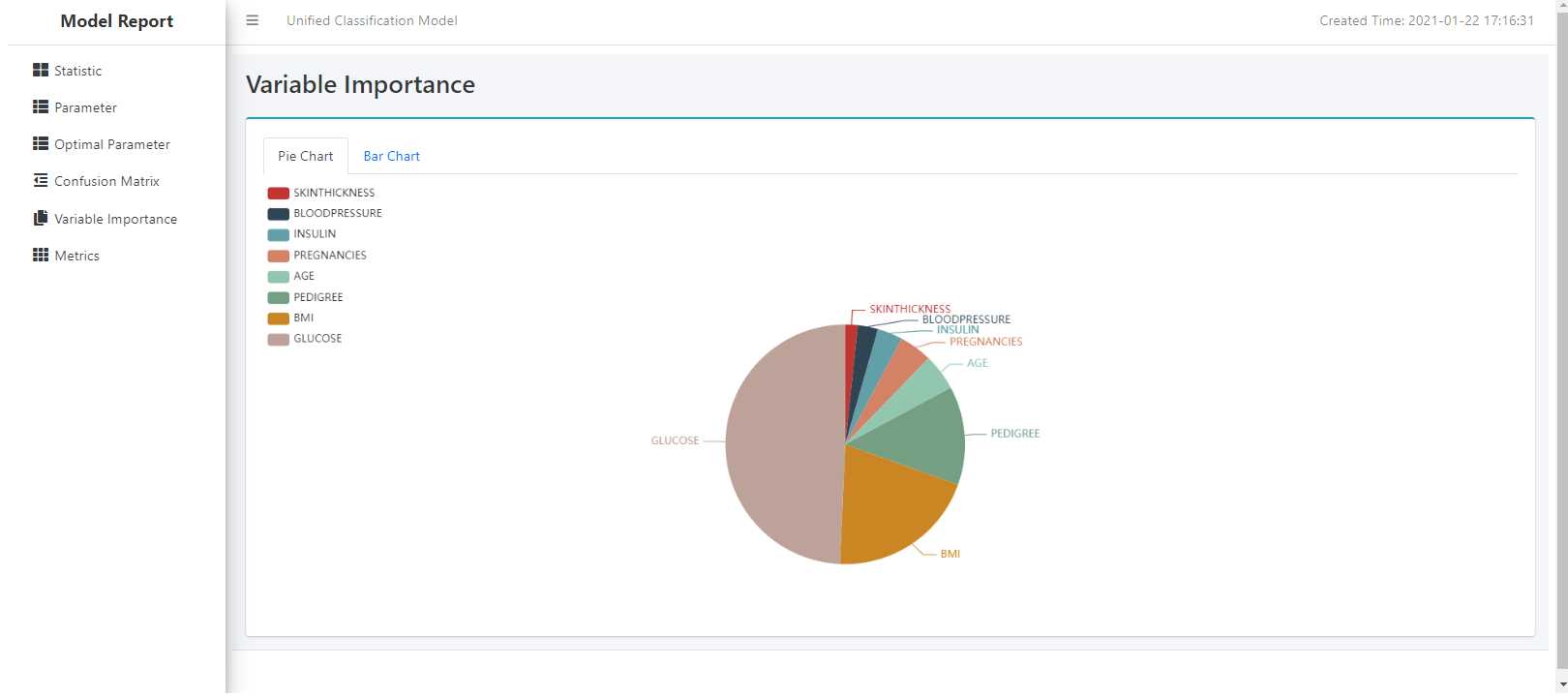
Visualizers Module
hana-ml provides various functions to visualize the dataset and model. The list is shown below:
hana_ml.visualizers.eda: offers a series of plot functions, e.g. Distribution plot, Pie plot and Correlation plot.
hana_ml.visualizers.m4_sampling: M4 algorithm for sampling query.
hana_ml.visualizers.metrics: represents a visualizer for metrics.
hana_ml.visualizers.model_debriefing: visualize a tree model.
hana_ml.visualizers.dataset_report: analyze the dataset and generate a report in HTML format.
hana_ml.visualizers.shap: represents an explainer for Shapley values.
hana_ml.visualizers.unified_report: build report for PAL/APL models.
An UnifiedReport example is shown below.
# Import required modules
from hana_ml.algorithms.pal.model_selection import GridSearchCV
from hana_ml.algorithms.pal.model_selection import RandomSearchCV
# Create an UnifiedClassification object
hgc = UnifiedClassification('HybridGradientBoostingTree')
gscv = GridSearchCV(estimator=hgc,
param_grid={'learning_rate': [0.1, 0.4, 0.7, 1],
'n_estimators': [4, 6, 8, 10],
'split_threshold': [0.1, 0.4, 0.7, 1]},
train_control=dict(fold_num=5,
resampling_method='cv',
random_state=1,
ref_metric=['auc']),
scoring='error_rate')
gscv.fit(data=diabetes_train,
key='ID',
label='CLASS',
partition_method='stratified',
partition_random_state=1,
stratified_column='CLASS',
build_report=True)
To look at the dataset report
UnifiedReport(diabetes_train).build().display()

To see the model report
UnifiedReport(gscv.estimator).display()
Spatial and Graph Features
Python machine learning client for SAP HANA introduces additional engines that can be used for analytics focused on Geospatial and Graph or network modeled data.
The Geospatial features contain integration of these file types through the create_dataframe functions:
create_data_frame_from_shapefile (Sourced from shape files including dbf, shp, or zip formats).
create_data_frame_from_pandas (Sourced from csv with a given geometry column and spatial reference id).
The Graph features contain integration of the same file types as well as making use of existing graph workspaces.
The hana_ml.graph package contains the following ways to create a Graph object representation:
create_graph_from_dataframes (Sourced from csv pairs of vertices and edges).
create_graph_from_hana_dataframes (Sourced from SAP HANA dataframes).
Graph() (Main object created based on an existing graph workspace)
With the following methods the graph objects on the database can be discovered:
discover_graph_workspaces (Metadata of all workspaces)
discover_graph_workspace (Metadata of a specific workspace
Once a Graph object is created, it functions in a similar manner as the PAL and APL libraries which return Pandas Dataframes for the user. In the case of SAP HANA Graph the following functions are currently offered.
edges (Pandas Dataframe of the edge table or links in other terms).
vertices (Pandas Dataframe of the vertex table or nodes in other terms).
has_vertices (Check if vertices exist in a graph)
source (Find a source vertex for an edge)
target (Find a target vertex for an edge)
drop (Delete a graph workspace)
The hana_ml.graph.algorithms package contains a list of algorithms that can be applied to an graph object:
Neighbors (Pandas Dataframe of the vertices that are connected to a given vertex key).
NeighborsSubgraph (Pandas Dataframe of the vertices that are connected to a given vertex key and a Pandas Dataframe of the edges included).
ShortestPath (Pandas Dataframe of the vertices that are on the shortest path between source and target vertex keys and a Pandas Dataframe of the edges that make the path).
KShortestPath (Top-k shortest paths)
Summary
Python machine learning client for SAP HANA (hana-ml) provides a set of Python APIs and functions for creating and manipulating SAP HANA DataFrames, training and scoring Machine Learning models. These functions ensure that the model training and prediction executes directly in SAP HANA. This offers better performance by executing close to the data, while ensuring there is no data transfer between the client and the server.